Models
"All models are wrong. But some are useful." - George Box

Models
"All models are wrong. But some are useful." - George Box
All of Statistics:
Observedi=^Modeli+Errori
Visualizing R2
- Total Variation in Y: Areas A + C
TSS=n∑i=1(Yi−ˉY)2
- Variation in Y explained by X: Area C
ESS=n∑i=1(^Yi−ˉY)2
- Unexplained variation in Y: Area A
SSE=n∑i=1(^ui)2
R2=ESSTSS=CA+C
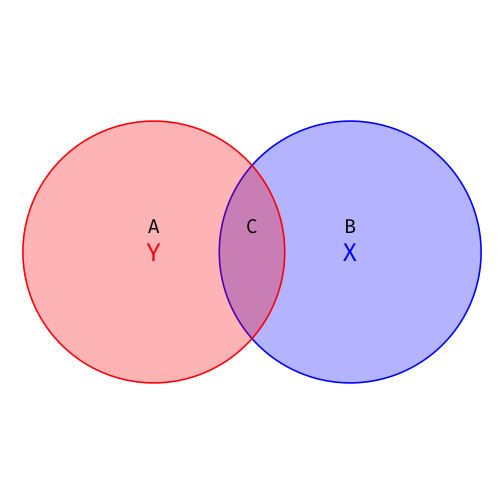
Visualizing R2
# make a function to calc. sum of sq. devssum_sq <- function(x){sum((x - mean(x))^2)}# find total sum of squaresTSS <- school_reg %>% augment() %>% summarize(TSS = sum_sq(testscr))# find explained sum of squaresESS <- school_reg %>% augment() %>% summarize(TSS = sum_sq(.fitted))# look at them and divide to get R^2tribble( ~ESS, ~TSS, ~R_sq, ESS, TSS, ESS/TSS ) %>% knitr::kable()| ESS | TSS | R_sq |
|---|---|---|
| 7794.11 | 152109.6 | 0.0512401 |
R2=ESSTSS=CA+C=0.05
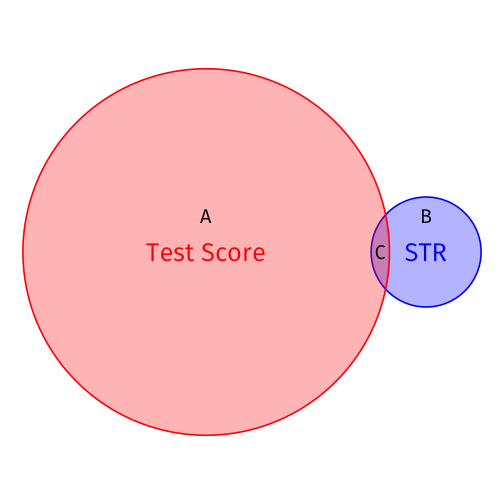
Recall: The Two Big Problems with Data
- We use econometrics to identify causal relationships and make inferences about them
Problem for identification: endogeneity
- X is exogenous if its variation is unrelated to other factors (u) that affect Y
- X is endogenous if its variation is related to other factors (u) that affect Y
Problem for inference: randomness
- Data is random due to natural sampling variation
- Taking one sample of a population will yield slightly different information than another sample of the same population


Inferential Statistics and Sampling Distributions
Inferential statistics analyzes a sample to make inferences about a much larger (unobservable) population
Population: all possible individuals that match some well-defined criterion of interest
- Characteristics about (relationships between variables describing) populations are called “parameters”
Sample: some portion of the population of interest to represent the whole
- Samples examine part of a population to generate statistics used to estimate population parameters

I.I.D. Samples
If we collect many samples, and each sample is randomly drawn from the population (and then replaced), then the distribution of samples is said to be independently and identically distributed (i.i.d.)
Each sample is independent of each other sample (due to replacement)
Each sample comes from the identical underlying population distribution

The Sampling Distribution of OLS Estimators
Calculating OLS estimators for a sample makes the OLS estimators themselves random variables:
Draw of i is random ⟹ value of each (Xi,Yi) is random ⟹ ^β0,^β1 are random
Taking different samples will create different values of ^β0,^β1
Therefore, ^β0,^β1 each have a sampling distribution across different samples
The Sampling Distribution of ^β1 I
The CLT allows us to approximate the sampling distributions of ^β0 and ^β1 as normal
We care about ^β1 (slope) since it has economic meaning, rarely about ^β0 (intercept)
^β1∼N(E[^β1],σ^β1)
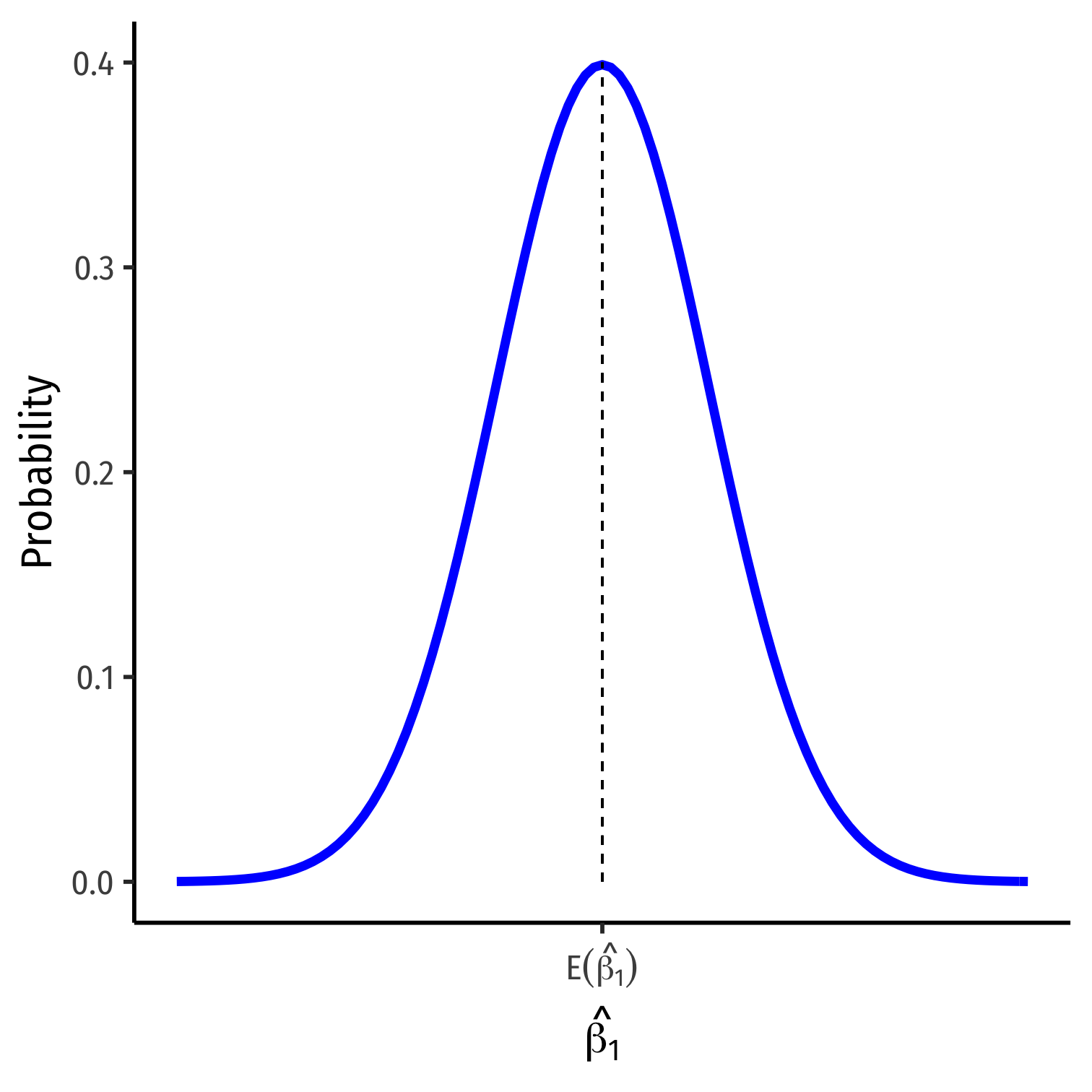
The Sampling Distribution of ^β1 II
^β1∼N(E[^β1],σ^β1)
- We want to know:
E[^β1]; what is the center of the distribution? (today)
σ^β1; how precise is our estimate? (next class)
Assumptions about Errors I
In order to talk about E[^β1], we need to talk about u
Recall: u is a random variable, and we can never measure the error term

Assumptions about Errors II
- We make 4 critical assumptions about u:
Assumptions about Errors II
- We make 4 critical assumptions about u:
- The expected value of the residuals is 0
E[u]=0
Assumptions about Errors II
- We make 4 critical assumptions about u:
The expected value of the residuals is 0 E[u]=0
The variance of the residuals over X is constant: var(u|X)=σ2u
Assumptions about Errors II
- We make 4 critical assumptions about u:
The expected value of the residuals is 0 E[u]=0
The variance of the residuals over X is constant: var(u|X)=σ2u
Errors are not correlated across observations: cor(ui,uj)=0∀i≠j
Assumptions about Errors II
- We make 4 critical assumptions about u:
The expected value of the residuals is 0 E[u]=0
The variance of the residuals over X is constant: var(u|X)=σ2u
Errors are not correlated across observations: cor(ui,uj)=0∀i≠j
There is no correlation between X and the error term: cor(X,u)=0 or E[u|X]=0
Assumptions 1 and 2: Errors are i.i.d.
The expected value of the residuals is 0 E[u]=0
The variance of the residuals over X is constant: var(u|X)=σ2u
- The first two assumptions ⟹ errors are i.i.d., drawn from the same distribution with mean 0 and variance σ2u
Assumption 2: Homoskedasticity
The variance of the residuals over X is constant: var(u|X)=σ2u
Assumption 2 implies that errors are “homoskedastic”: they have the same variance across X
Often this assumption is violated: errors may be “heteroskedastic”: they do not have the same variance across X
This is a problem for inference, but we have a simple fix for this (next class)
Assumption 3: No Serial Correlation
Errors are not correlated across observations: cor(ui,uj)=0∀i≠j
For simple cross-sectional data, this is rarely an issue
Time-series & panel data nearly always contain serial correlation or autocorrelation between errors
e.g. "this week's sales look a lot like last weel's sales, which look like...etc"
There are fixes to deal with autocorrelation (coming much later)
Assumption 4: The Zero Conditional Mean Assumption
No correlation between X and the error term: cor(X,u)=0
This is the absolute killer assumption, because it assumes exogeneity
Often called the Zero Conditional Mean assumption: E[u|X]=0
"Does knowing X give me any useful information about u?"
- If yes: model is endogenous, biased and not-causal!
Sidenote: Statistical Estimators II
- What makes one estimator (e.g. ˉH) better than another (e.g. H1)?†
Biasedness: does the estimator give us the true parameter on average?
Efficiency: an estimator with a smaller variance is better
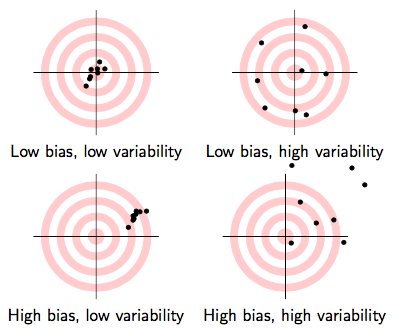
† Technically, we also care about consistency: minimizing uncertainty about the correct value. The Law of Large Numbers, similar to CLT, permits this. We don't need to get too advanced about probability in this class.
Exogeneity and Unbiasedness I
^β1 is the Best Linear Unbiased Estimator (BLUE) estimator of β1 when X is exogenous†
No systematic difference, on average, between sample values of ^β1 and the true population β1:
E[^β1]=β1
- Does not mean that each sample gives us ^β1=β1, only the estimation procedure will, on average, yield the correct value
† The proof for this is known as the famous Gauss-Markov Theorem. See today's class notes for a simplified proof.