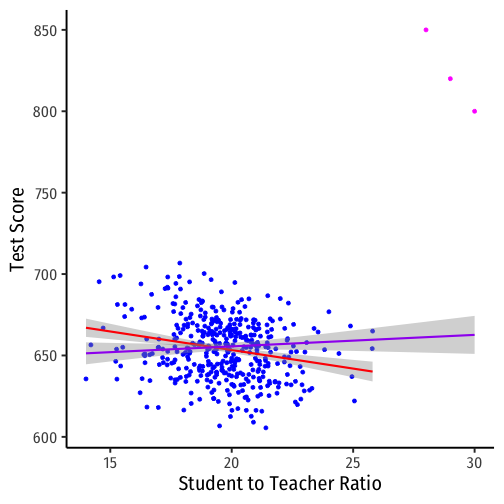
The Sampling Distribution of ^β1
^β1∼N(E[^β1],σ^β1)
- Center of the distribution (last class)
- E[^β1]=β1†
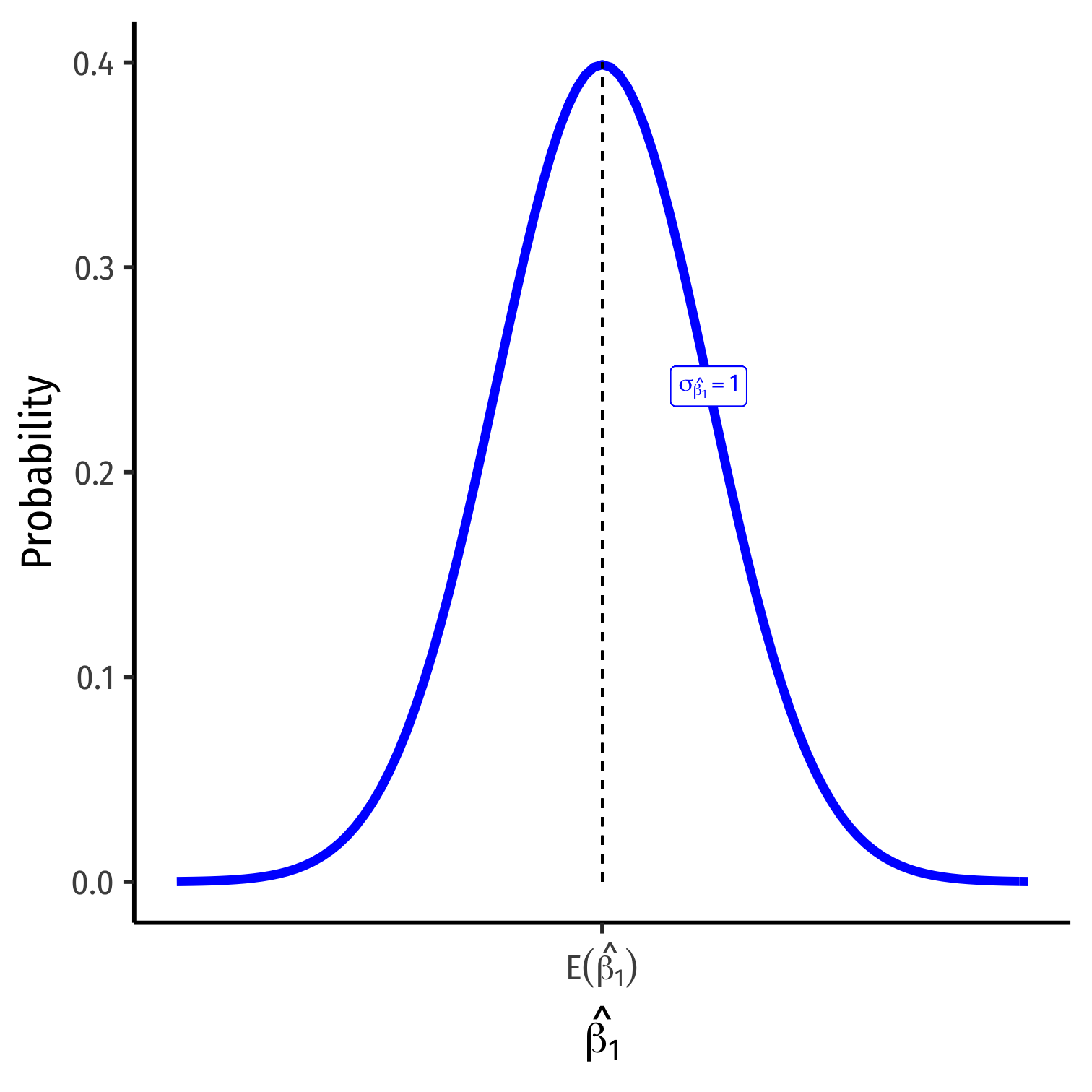
The Sampling Distribution of ^β1
^β1∼N(E[^β1],σ^β1)
Center of the distribution (last class)
- E[^β1]=β1†
How precise is our estimate? (today)
- Variance σ2^β1 or standard error‡ σ^β1
† Under the 4 assumptions about u (particularly, cor(X,u)=0).
‡ Standard “error” is the analog of standard deviation when talking about
the sampling distribution of a sample statistic (such as ˉX or ^β1).
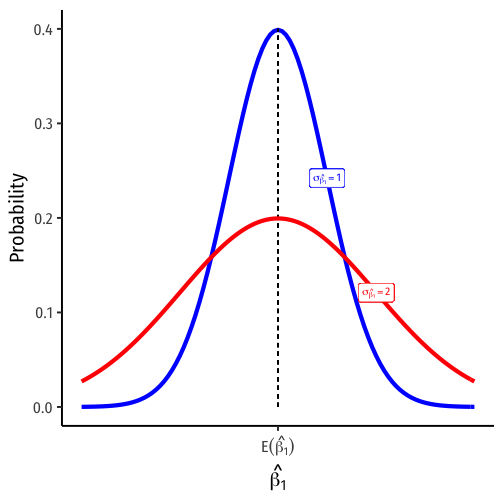
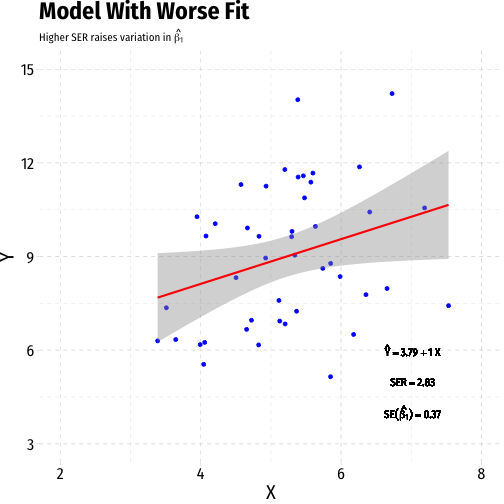
Variation in ^β1: Goodness of Fit
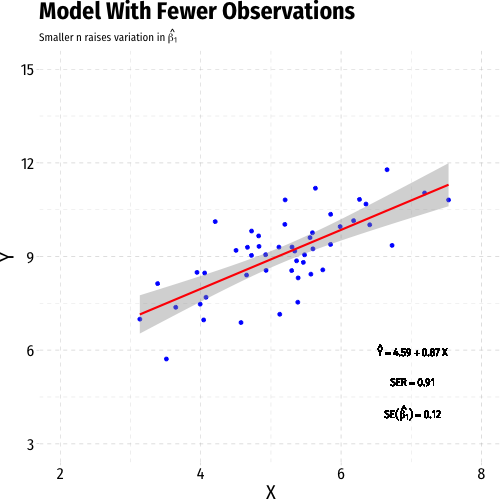
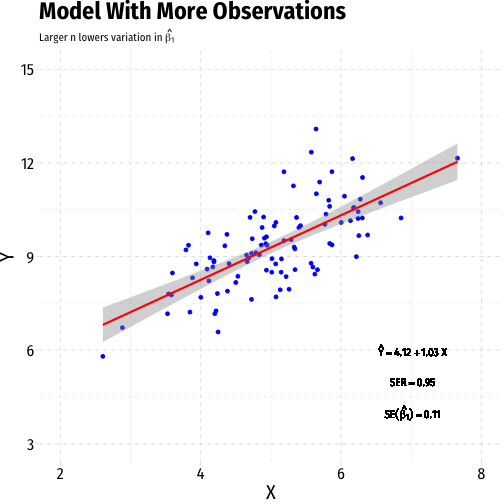
Variation in ^β1: Sample Size
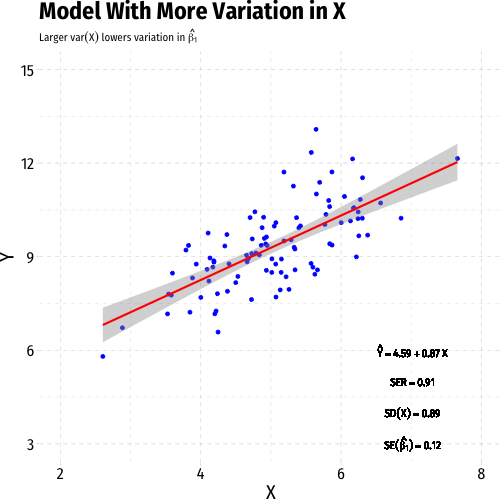
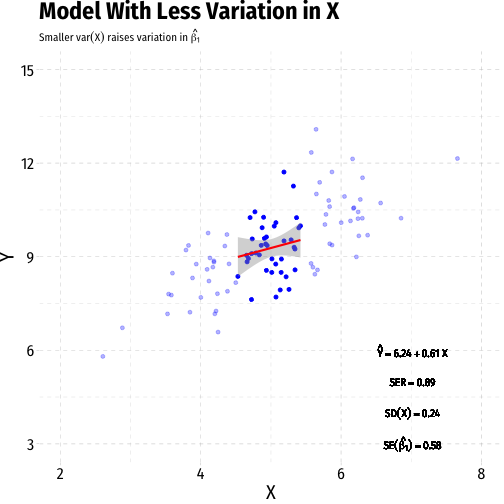
Variation in ^β1: Variation in X
Our Class Size Regression: Broom I

broom'stidy()function creates a tidy tibble of regression output
# load broomlibrary(broom)# tidy regression outputtidy(school_reg)## # A tibble: 2 × 5## term estimate std.error statistic p.value## <chr> <dbl> <dbl> <dbl> <dbl>## 1 (Intercept) 699. 9.47 73.8 6.57e-242## 2 str -2.28 0.480 -4.75 2.78e- 6Recap: Assumptions about Errors
- We make 4 critical assumptions about u:
The expected value of the residuals is 0 E[u]=0
The variance of the residuals over X is constant: var(u|X)=σ2u
Errors are not correlated across observations: cor(ui,uj)=0∀i≠j
There is no correlation between X and the error term: cor(X,u)=0 or E[u|X]=0

Plotting Residuals
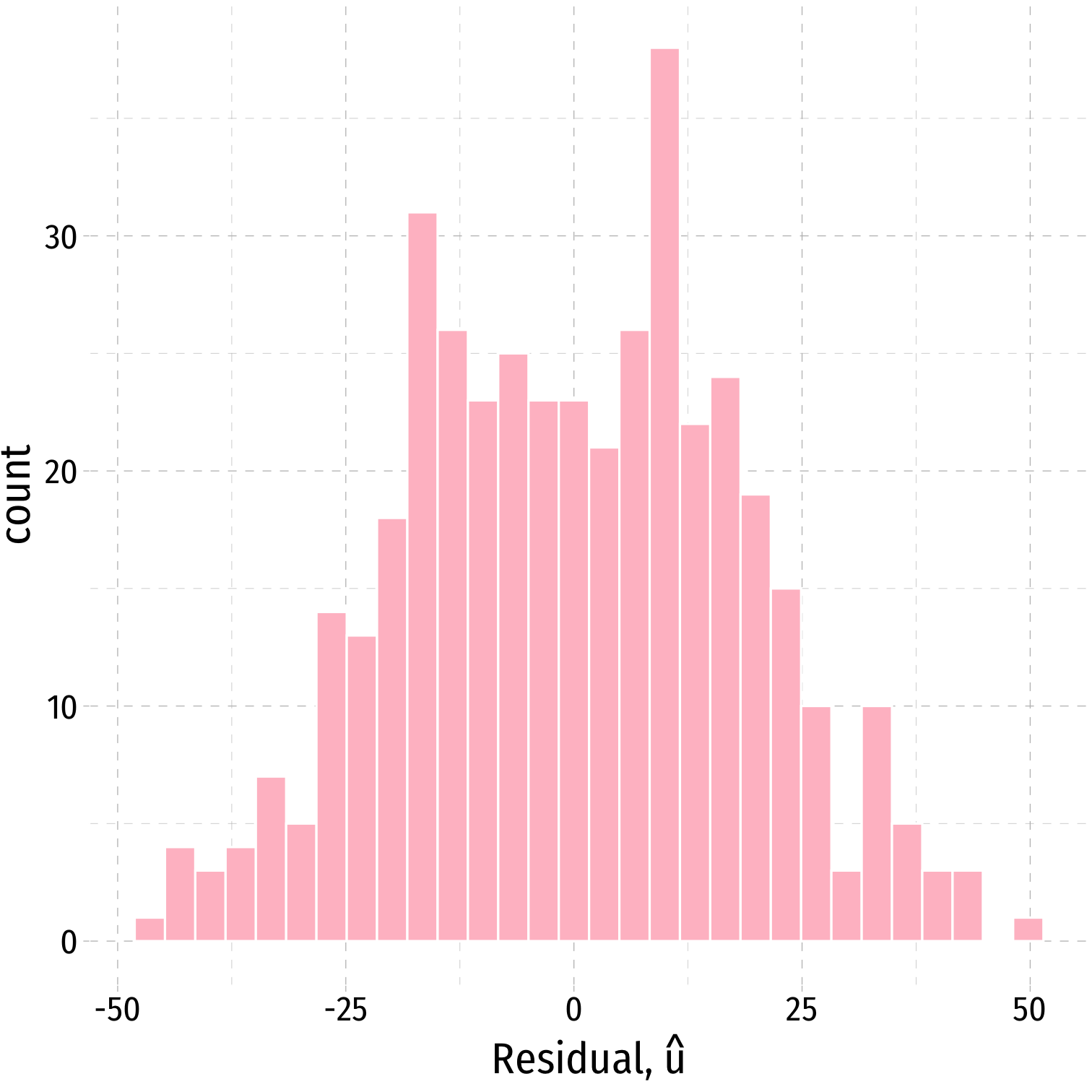
ggplot(data = aug_reg)+ aes(x = .resid)+ geom_histogram(color="white", fill = "pink")+ labs(x = expression(paste("Residual, ", hat(u))))+ theme_pander(base_family = "Fira Sans Condensed", base_size=20)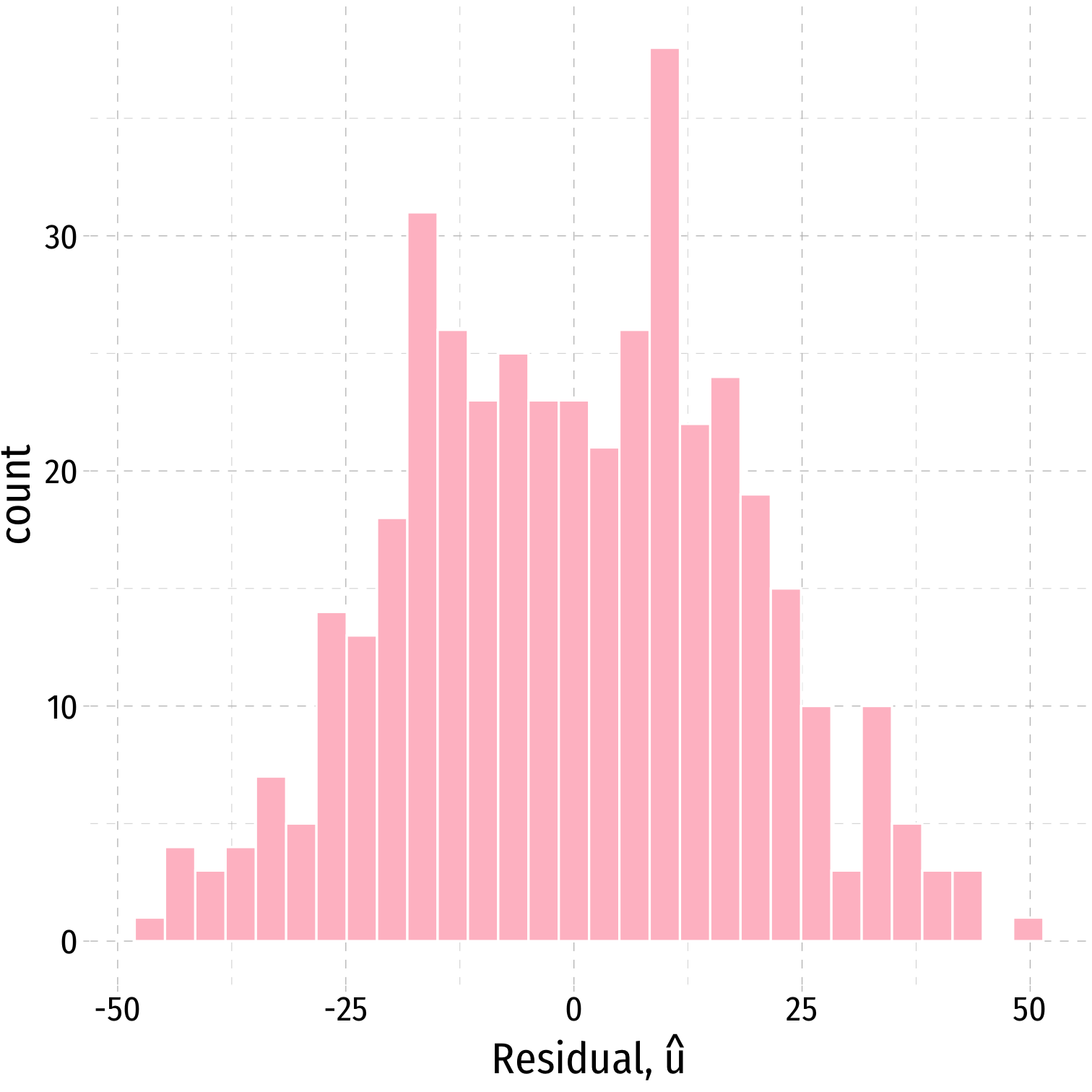
Plotting Residuals
ggplot(data = aug_reg)+ aes(x = .resid)+ geom_histogram(color="white", fill = "pink")+ labs(x = expression(paste("Residual, ", hat(u))))+ theme_pander(base_family = "Fira Sans Condensed", base_size=20)- Just to check:
aug_reg %>% summarize(E_u = mean(.resid), sd_u = sd(.resid))| E_u | sd_u |
|---|---|
| 3.7e-13 | 18.6 |
Residual Plot
- We often plot a residual plot to see any odd patterns about residuals
- x-axis are X values (
str) - y-axis are u values (
.resid)
- x-axis are X values (
ggplot(data = aug_reg)+ aes(x = str, y = .resid)+ geom_point(color="blue")+ geom_hline(aes(yintercept = 0), color="red")+ labs(x = "Student to Teacher Ratio", y = expression(paste("Residual, ", hat(u))))+ theme_pander(base_family = "Fira Sans Condensed", base_size=20)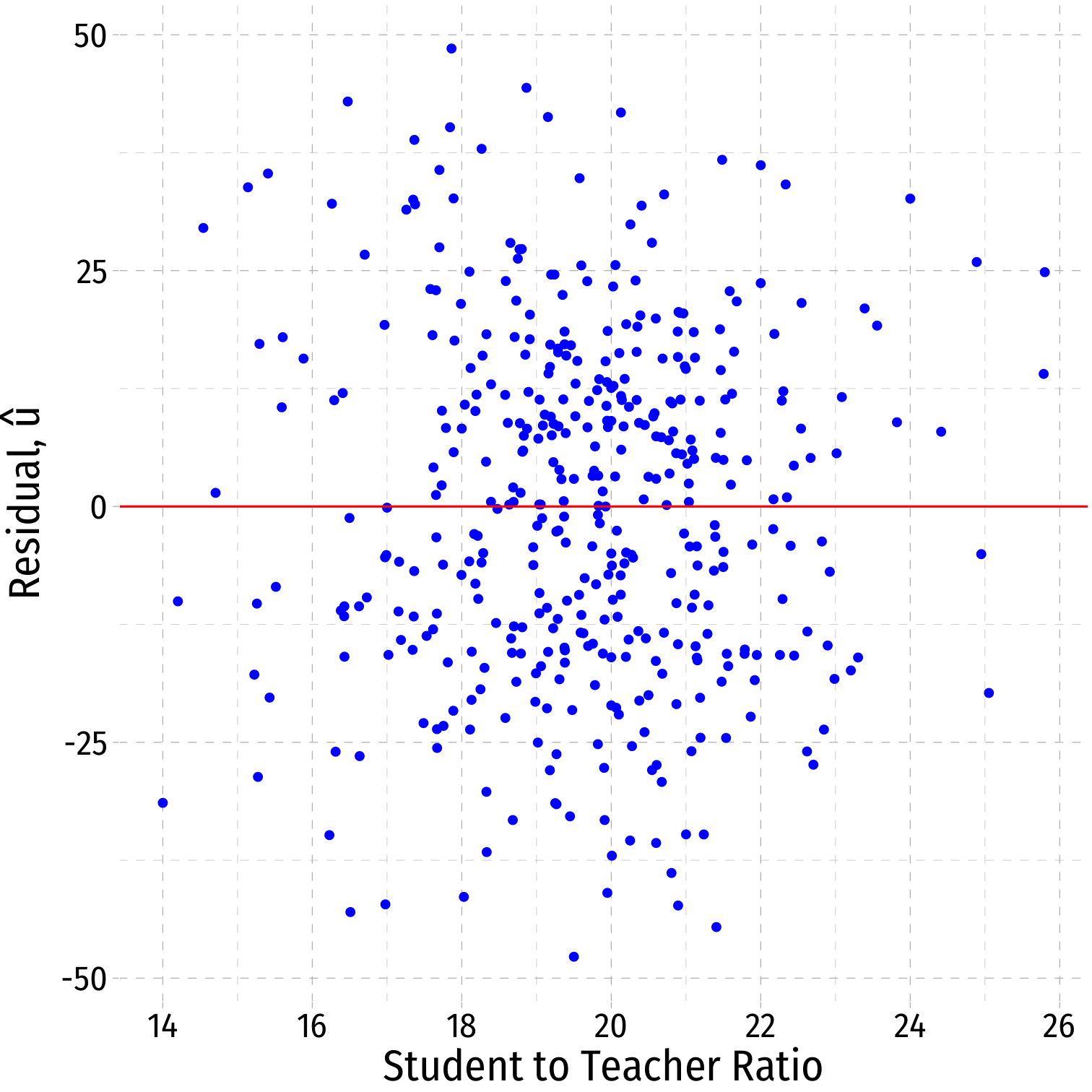
Homoskedasticity
"Homoskedasticity:" variance of the residuals over X is constant, written: var(u|X)=σ2u
Knowing the value of X does not affect the variance (spread) of the errors
Heteroskedasticity I
"Heteroskedasticity:" variance of the residuals over X is NOT constant: var(u|X)≠σ2u
This does not cause ^β1 to be biased, but it does cause the standard error of ^β1 to be incorrect
This does cause a problem for inference!
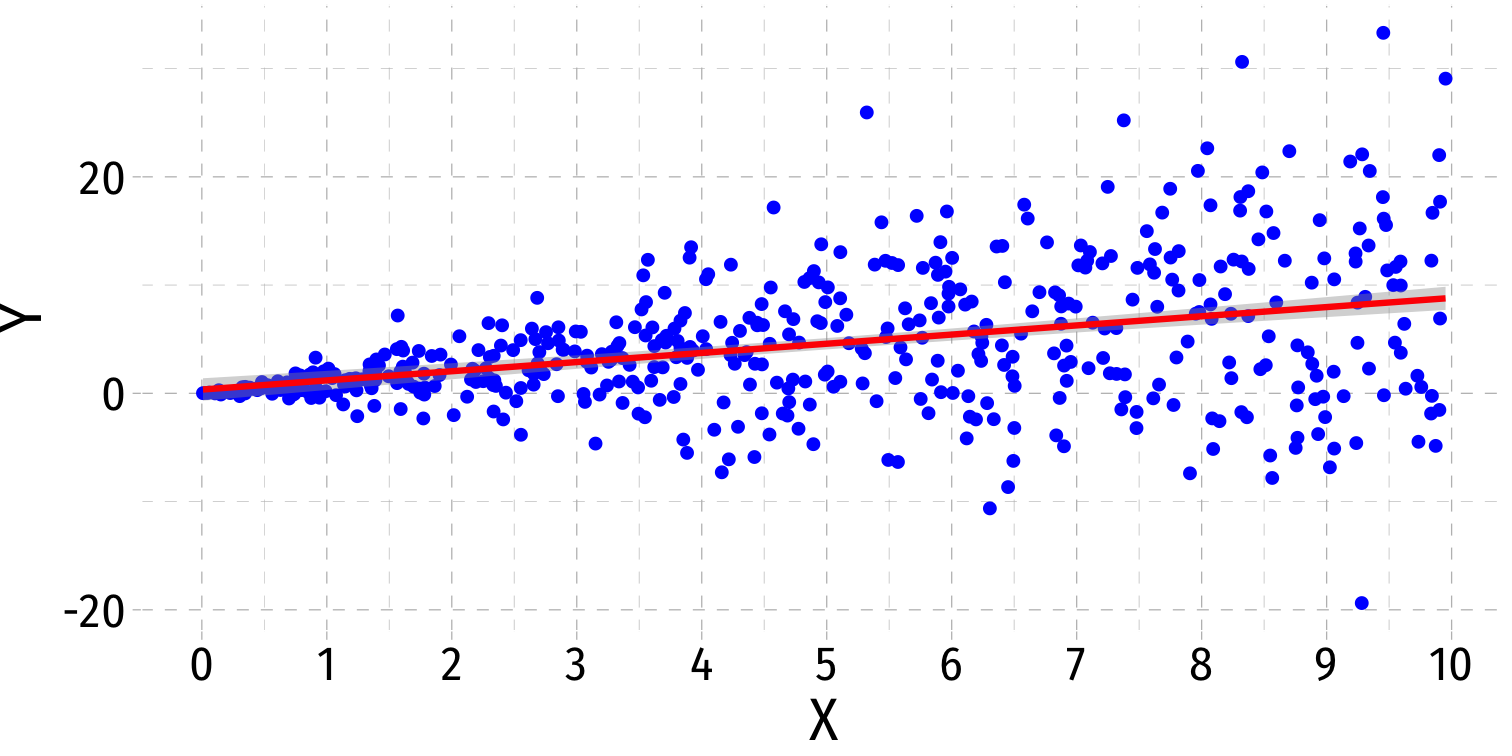
Visualizing Heteroskedasticity I
- Our original scatterplot with regression line
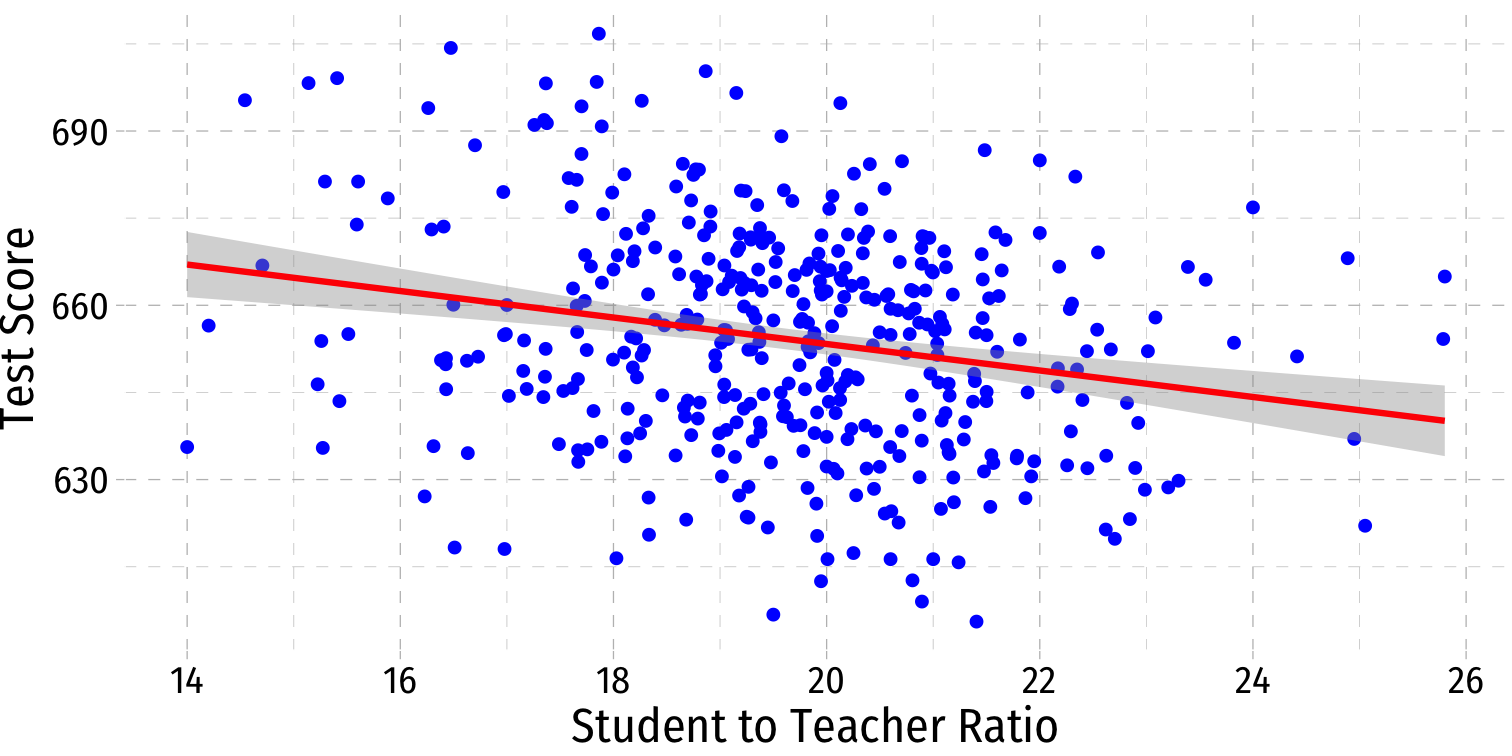
Visualizing Heteroskedasticity I
Our original scatterplot with regression line
Does the spread of the errors change over different values of str?
- No: homoskedastic
- Yes: heteroskedastic
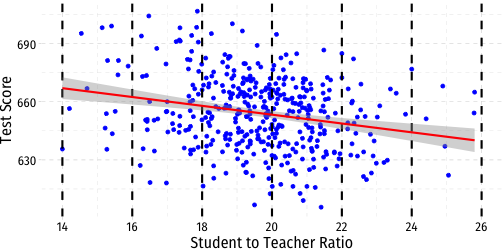
Visualizing Heteroskedasticity I
Our original scatterplot with regression line
Does the spread of the errors change over different values of str?
- No: homoskedastic
- Yes: heteroskedastic
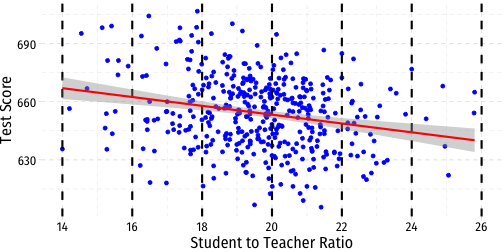
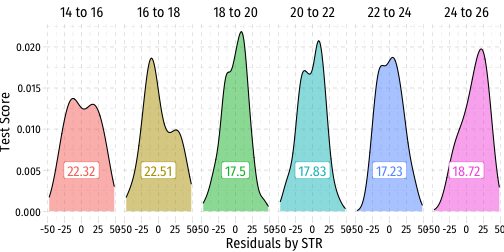
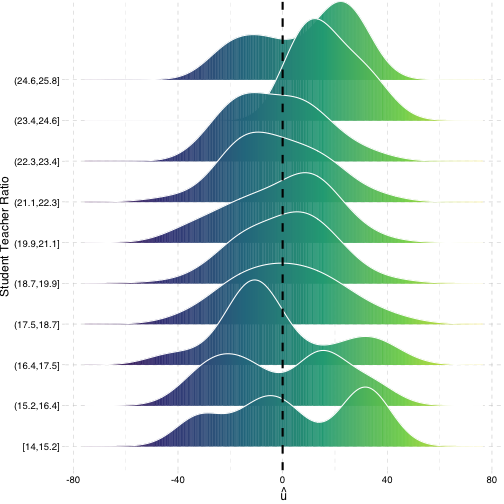
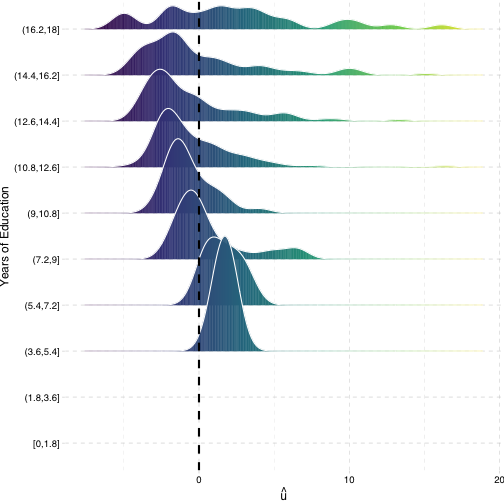
Heteroskedasticity: Another View
Using the
ggridgespackagePlotting the (conditional) distribution of errors by STR
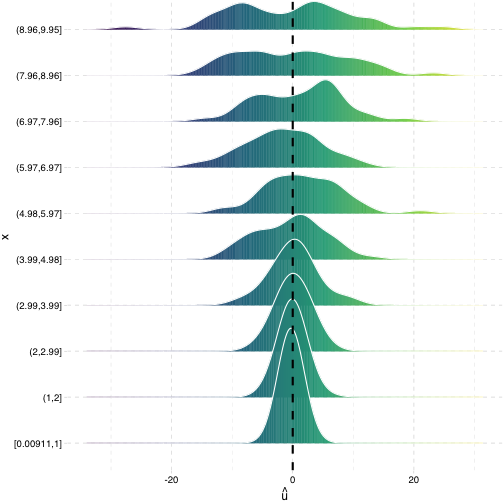
See that the variation in errors (ˆu) changes across class sizes!
More Obvious Heteroskedasticity
- Visual cue: data is "fan-shaped"
- Data points are closer to line in some areas
- Data points are more spread from line in other areas
More Obvious Heteroskedasticity
- Visual cue: data is "fan-shaped"
- Data points are closer to line in some areas
- Data points are more spread from line in other areas
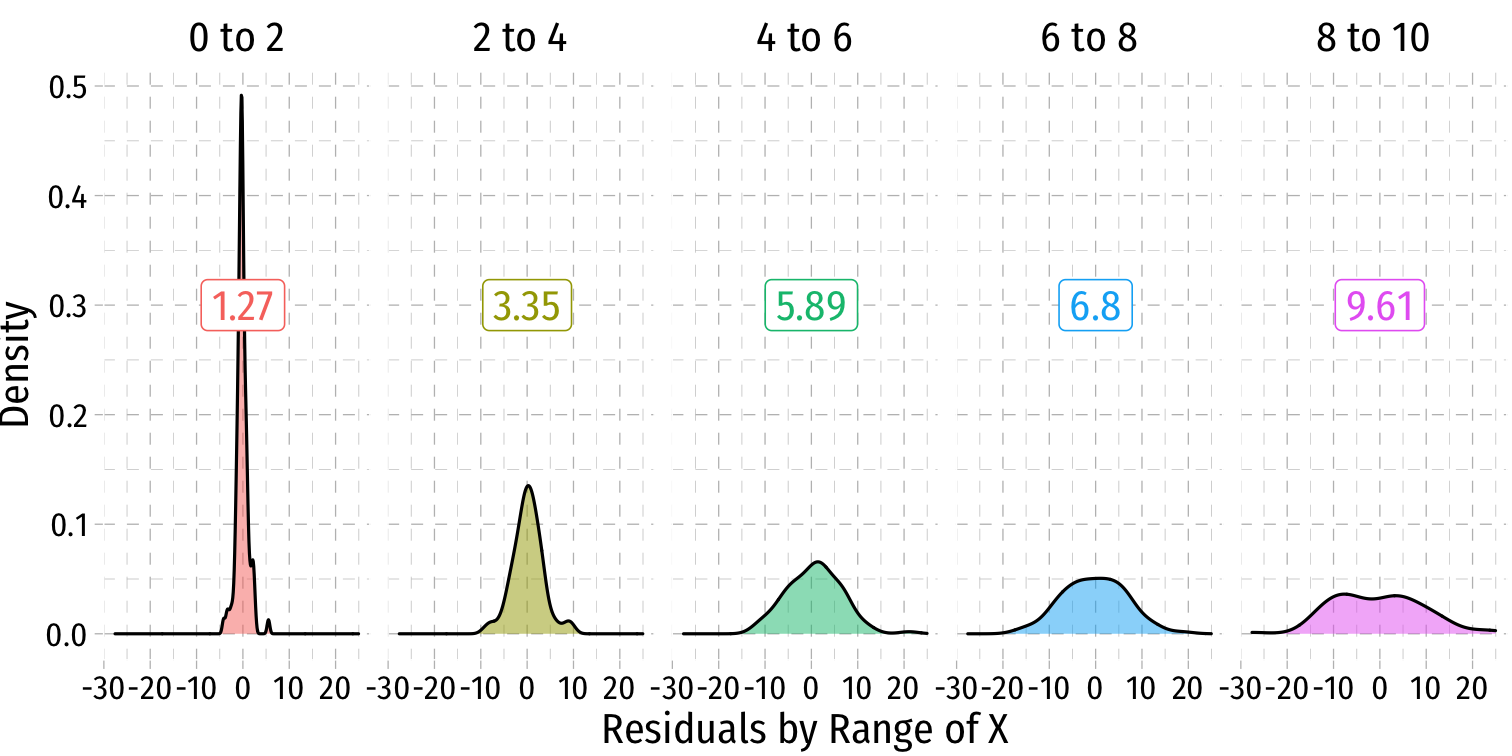
Heteroskedasticity: Another View
Using the
ggridgespackagePlotting the (conditional) distribution of errors by x
What Might Cause Heteroskedastic Errors?
^wagei=^β0+^β1educi
| Wage | |
|---|---|
| Intercept | -0.90 |
| (0.68) | |
| Years of Schooling | 0.54 *** |
| (0.05) | |
| N | 526 |
| R-Squared | 0.16 |
| SER | 3.38 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | |
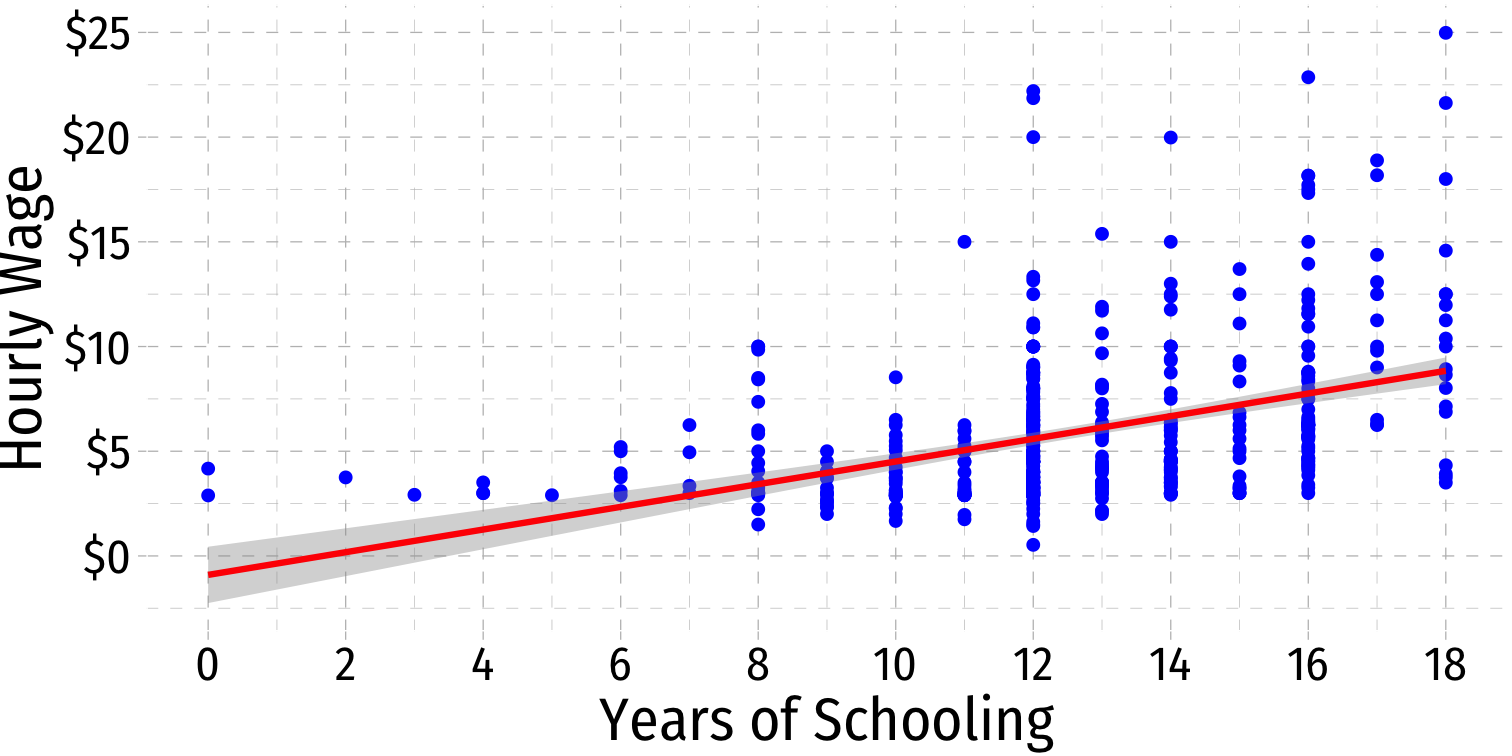
What Might Cause Heteroskedastic Errors?
^wagei=^β0+^β1educi
| Wage | |
|---|---|
| Intercept | -0.90 |
| (0.68) | |
| Years of Schooling | 0.54 *** |
| (0.05) | |
| N | 526 |
| R-Squared | 0.16 |
| SER | 3.38 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | |
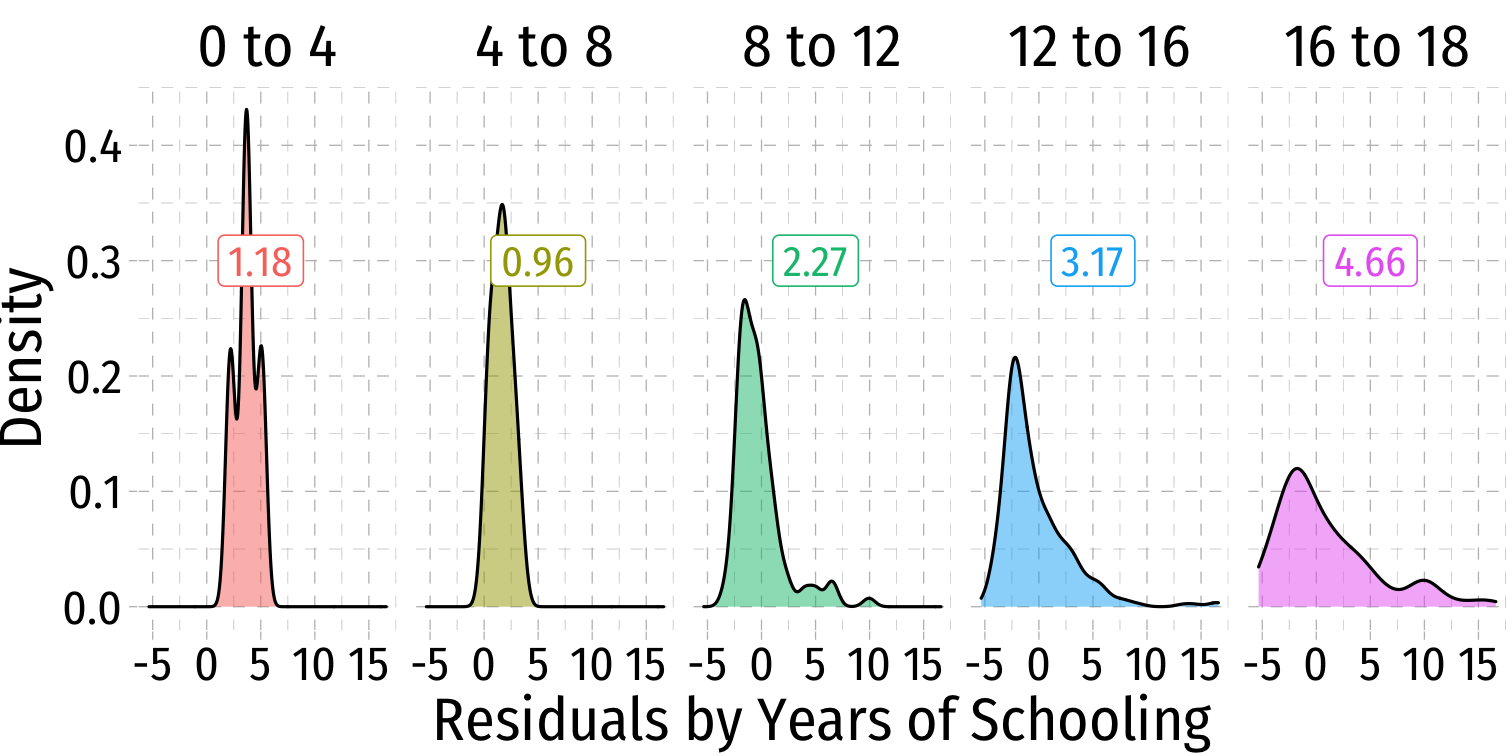
Heteroskedasticity: Another View
Using the
ggridgespackagePlotting the (conditional) distribution of errors by education
Assumption 3: No Serial Correlation
Errors are not correlated across observations: cor(ui,uj)=0∀i≠j
For simple cross-sectional data, this is rarely an issue
Time-series & panel data nearly always contain serial correlation or autocorrelation between errors
Errors may be clustered
- by group: e.g. all observations from Maryland, all observations from Virginia, etc.
- by time: GDP in 2006 around the world, GDP in 2008 around the world, etc.
We'll deal with these fixes when we talk about panel data (or time-series if necessary)
Outliers Can Bias OLS! I
Outliers can affect the slope (and intercept) of the line and add bias
- May be result of human error (measurement, transcribing, etc)
- May be meaningful and accurate
In any case, compare how including/dropping outliers affects regression and always discuss outliers!
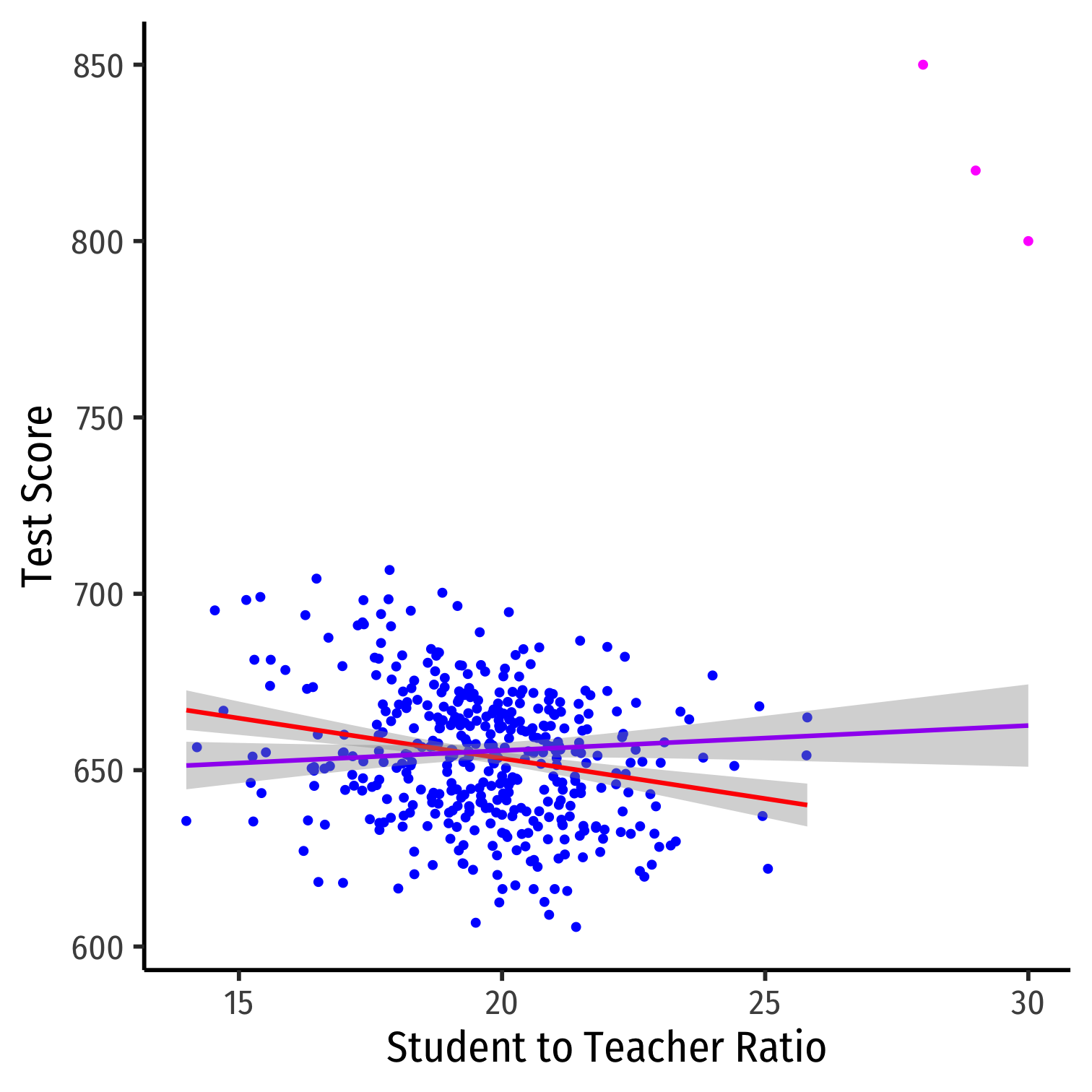
Outliers Can Bias OLS! II
huxreg("No Outliers" = school_reg, "Outliers" = school_outlier_reg, coefs = c("Intercept" = "(Intercept)", "STR" = "str"), statistics = c("N" = "nobs", "R-Squared" = "r.squared", "SER" = "sigma"), number_format = 2)| No Outliers | Outliers | |
|---|---|---|
| Intercept | 698.93 *** | 641.40 *** |
| (9.47) | (11.21) | |
| STR | -2.28 *** | 0.71 |
| (0.48) | (0.57) | |
| N | 420 | 423 |
| R-Squared | 0.05 | 0.00 |
| SER | 18.58 | 23.76 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||