Writing & Reading Empirical Papers
ECON 480 • Econometrics • Fall 2021
Ryan Safner
Assistant Professor of Economics
safner@hood.edu
ryansafner/metricsF21
metricsF21.classes.ryansafner.com
Your Research Question
- A good paper has a specific research question that you will ask and provide evidence towards a clear, quantifiable answer. Good research questions are:
Your Research Question
- A good paper has a specific research question that you will ask and provide evidence towards a clear, quantifiable answer. Good research questions are:
- A claim about something
- Capital punishment is the most efficient deterrent for violent crimes.
- Women are paid, on average, 33% less than men performing the same work.
Your Research Question
- A good paper has a specific research question that you will ask and provide evidence towards a clear, quantifiable answer. Good research questions are:
A claim about something
- Capital punishment is the most efficient deterrent for violent crimes.
- Women are paid, on average, 33% less than men performing the same work.
As specific as possible, given the length constraints
- Do candidates that spend more money than their opponents tend to win Congressional races?
Your Research Question
- A good paper has a specific research question that you will ask and provide evidence towards a clear, quantifiable answer. Good research questions are:
A claim about something
- Capital punishment is the most efficient deterrent for violent crimes.
- Women are paid, on average, 33% less than men performing the same work.
As specific as possible, given the length constraints
- Do candidates that spend more money than their opponents tend to win Congressional races?
Testable, with data that can provide some evidence one way or another
- One study will never be “the” definitive proof of something, only suggestive evidence
Structure of an Empirical Paper
Introduction
Literature Review
Theory/Model
Data Description
Empirical Model
Results/Implications
Bibliography
Introduction
Get to your research question ASAP! Make it the first sentence even.
Hook your reader
- Who cares? Why is this important? Why is this relevant? How does this affect people?
- Statistics and background information can often help
- Who cares? Why is this important? Why is this relevant? How does this affect people?
Introduction
Get to your research question ASAP! Make it the first sentence even.
Hook your reader
- Who cares? Why is this important? Why is this relevant? How does this affect people?
- Statistics and background information can often help
- Who cares? Why is this important? Why is this relevant? How does this affect people?
Example: As a student writing an empirical research paper, does writing a longer paper earn a higher grade on the assignment?
Introduction II
- State your research question clearly and quickly
Introduction II
State your research question clearly and quickly
Do NOT write a “blog post” about how you became interested in the question, or all the work (and dead-ends) that led you on the journey to reaching your final answer
- Nobody cares about the labor pains, they just want to see the baby!
Introduction II
State your research question clearly and quickly
Do NOT write a “blog post” about how you became interested in the question, or all the work (and dead-ends) that led you on the journey to reaching your final answer
- Nobody cares about the labor pains, they just want to see the baby!
Provide an outline of the rest of the paper:
- Why your question matters
- How you answer the question in this paper
- What your identification strategy is and what models you use
- What data you use
- What your most important results are
Introduction III
Example: I estimate the relationship between paper length and grades by using a simple OLS regression using sample data collected from previous classes. I find that there is a weak positive effect, that students who write longer papers earn higher grades. On average, for every additional page written, grades improve by less than a point. These results are robust to a number of different model specifications and controls.
Introduction IV
Most people do not write enough in their introductions
Consider the incentives of a (skimming) reader pressed for time
- If someone only skims your intro, what do you want them to know??
My rough suggestion: make your introduction about 15-20% of your paper:
| Paper Length | Intro Length |
|---|---|
| 5 pages | 1-1.5 pages |
| 10 pages | 2-2.5 pages |
| 30 pages | 5 pages |
Literature Review
Literature Review can be summarized into the introduction or given its' own section (debatable)
No work is totally original. It's okay!
- What have other relevant researchers written and discovered about your topic?
- What data and models did they use? What did they find?
- How does your paper connect and stand apart from what's been done?
- Does your paper use different data? A different model? Different controls?
Theory
This is an economics course, so you must describe some economic theory behind the question you are asking and answering
Most scholarly papers have a formal economic model, which then generates predictions that they test for with data
You do not need a theoretical model, but you do need to discuss economic principles or concepts that are relevant
- Often there may be multiple theories that might conflict, or our expectations might not be clear (these are the best papers!)
- There may be a significant tradeoff between competing goals, values, or expectations
Theory II
Example: Students that write longer papers likely place higher value on their work and dedicate more resources towards improving its quality, resulting in higher grades.
However, some students may hope or believe that longer papers automatically lead to higher grades, and thus will merely put extra low quality filler in their paper to inflate the length. These papers turn out to be much worse quality, and these students likely earn lower grades as a result.
Data I
- Describe your data sources
- Who collected or compiled the data and how?
- e.g. government agencies, businesses, nonprofits, social surveys, etc.
- If you collected your own data (unlikely), what was your procedure?
- Who collected or compiled the data and how?
Data II
- Describe the data itself
- What are your variables? What—specifically, and in English—does each measure?
- How many observations do you have?
- If you transformed your variables—how and why?
- e.g. recoded into categories or dummies
- e.g. took logs or rescaled units
Data III
- Show your data! Show us basic summary statistics and any patterns
- Use your judgment: we don't want or need to see everything
- What do you think is interesting or important?
- Plots > Tables > Words > Nothing
Data III
Show your data! Show us basic summary statistics and any patterns
- Use your judgment: we don't want or need to see everything
- What do you think is interesting or important?
- Plots > Tables > Words > Nothing
Good ideas to always have:
- A table(s) of all variables used and their description
- A table(s) of summary statistics of variables
- A table of correlations of key variables (optional)
- Plots of (only) the most important variables & relationships (histograms, boxplots, scatterplots, etc)
Data: Variables
| Variable | Description |
|---|---|
| Grade | Grade on paper assignment (0-100) |
| Pages | Number of pages written |
| Final | Final course grade for student |
| Gender | Gender of student |
| Class | Class in which paper was assigned |
| School | School of class taught |
| Year | Year of class |
| Time | Time of day class met |
| Covid | Course during Covid? |
I collected data at the individual student level from all paper assignments that I have given over the 2013—2021 period at the 3 colleges I have taught at.
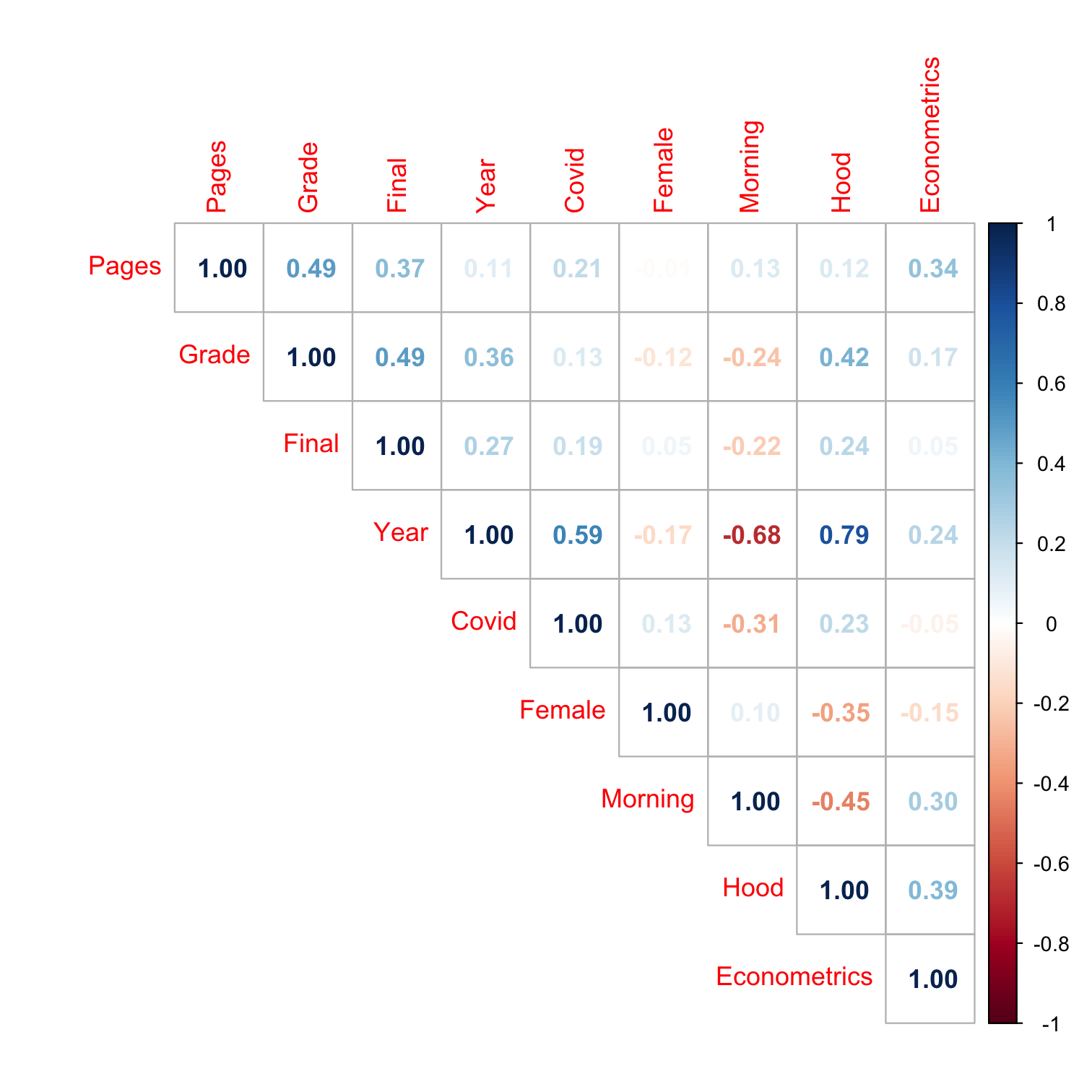
Data: Correlations
| Variable | Description |
|---|---|
| Grade | Grade on paper assignment (0-100) |
| Pages | Number of pages written |
| Final | Final course grade for student |
| Gender | Gender of student |
| Class | Course in which paper was assigned |
| School | College of course taught |
| Year | Year of class |
| Time | Time of day course met (Morning/Afternoon) |
| Covid | Course during Covid? |
Data: Summary Statistics of Quantitative Variables
| Variable | Obs | Min | Q1 | Median | Q3 | Max | Mean | Std. Dev. |
|---|---|---|---|---|---|---|---|---|
| Covid | 197 | 0.0 | 0 | 0.00 | 0 | 1.00 | 0.13 | 0.33 |
| Econometrics | 197 | 0.0 | 0 | 0.00 | 1 | 1.00 | 0.30 | 0.46 |
| Female | 197 | 0.0 | 0 | 0.00 | 1 | 1.00 | 0.40 | 0.49 |
| Final | 197 | 8.5 | 83 | 87.35 | 94 | 109.09 | 86.74 | 11.34 |
| Grade | 197 | 0.0 | 84 | 87.00 | 92 | 100.00 | 85.86 | 12.67 |
| Hood | 197 | 0.0 | 0 | 1.00 | 1 | 1.00 | 0.74 | 0.44 |
| Morning | 197 | 0.0 | 0 | 1.00 | 1 | 1.00 | 0.63 | 0.48 |
| Pages | 197 | 0.0 | 7 | 9.00 | 12 | 24.00 | 9.95 | 4.17 |
| Year | 197 | 2014.0 | 2014 | 2017.00 | 2019 | 2020.00 | 2016.80 | 2.09 |
Data: Counts of Categorical Variables I
| Year | n |
|---|---|
| 2014 | 51 |
| 2016 | 38 |
| 2017 | 39 |
| 2018 | 13 |
| 2019 | 30 |
| 2020 | 26 |
| Sex | n |
|---|---|
| Female | 78 |
| Male | 119 |
| Time | n |
|---|---|
| Afternoon | 72 |
| Morning | 125 |
| Class | n |
|---|---|
| Econometrics | 60 |
| Game Theory | 21 |
| HET | 11 |
| IEP | 51 |
| IO | 22 |
| Public Economics | 9 |
| Trade | 23 |
Data: Counts of Categorical Variables II
| School | n |
|---|---|
| GMU | 51 |
| Hood | 146 |
| Covid | n |
|---|---|
| 0 | 172 |
| 1 | 25 |
Data: Histogram I
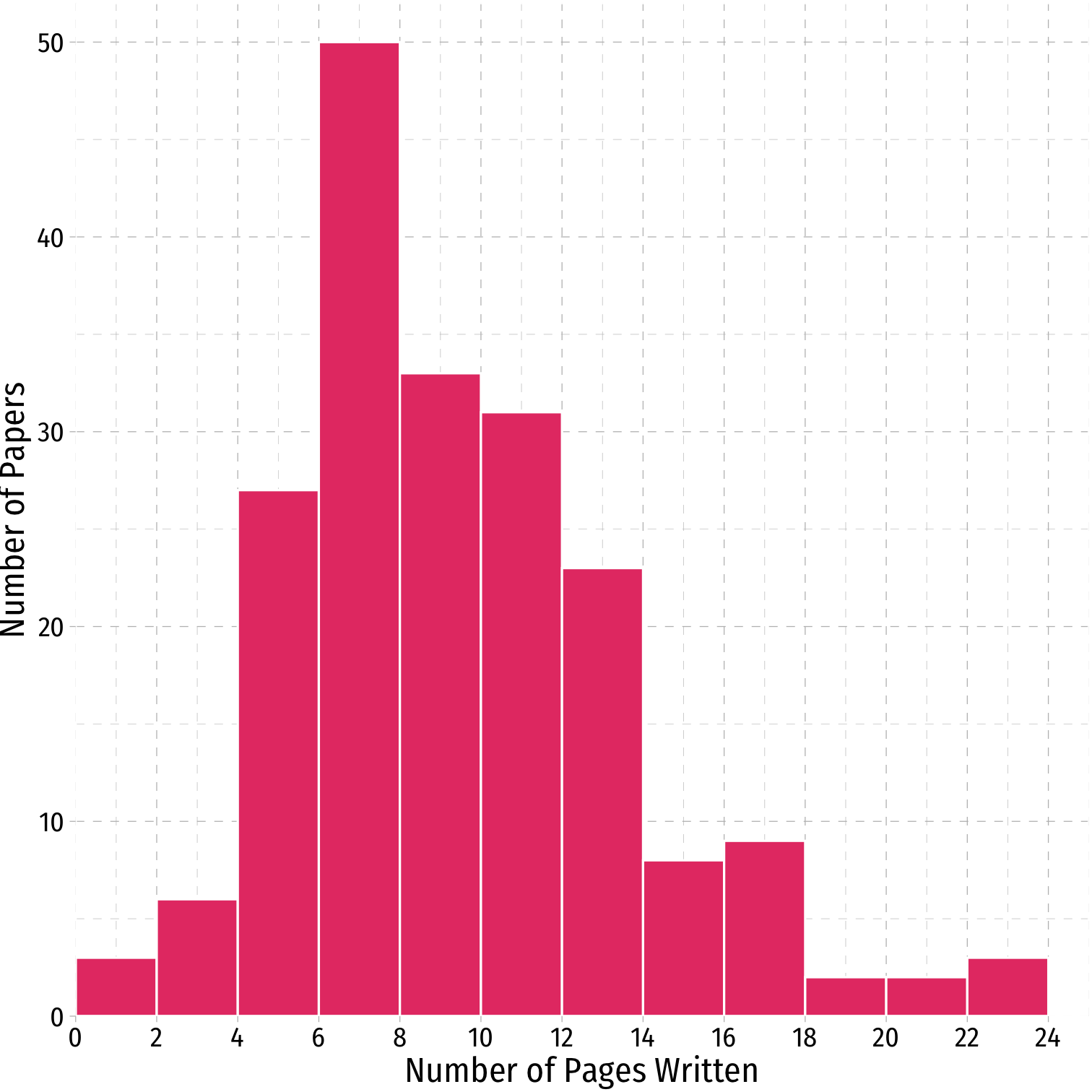
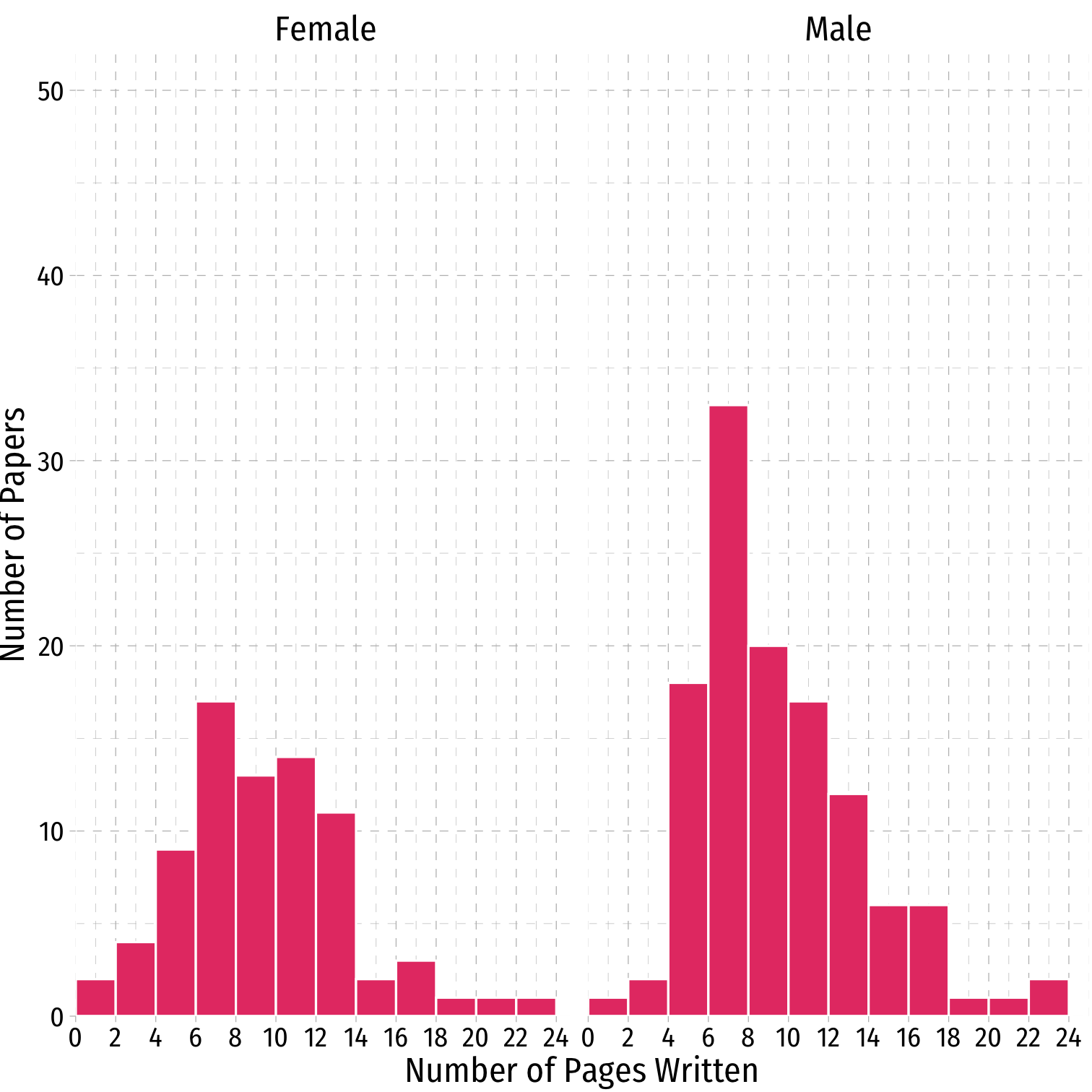
Data: Histogram II
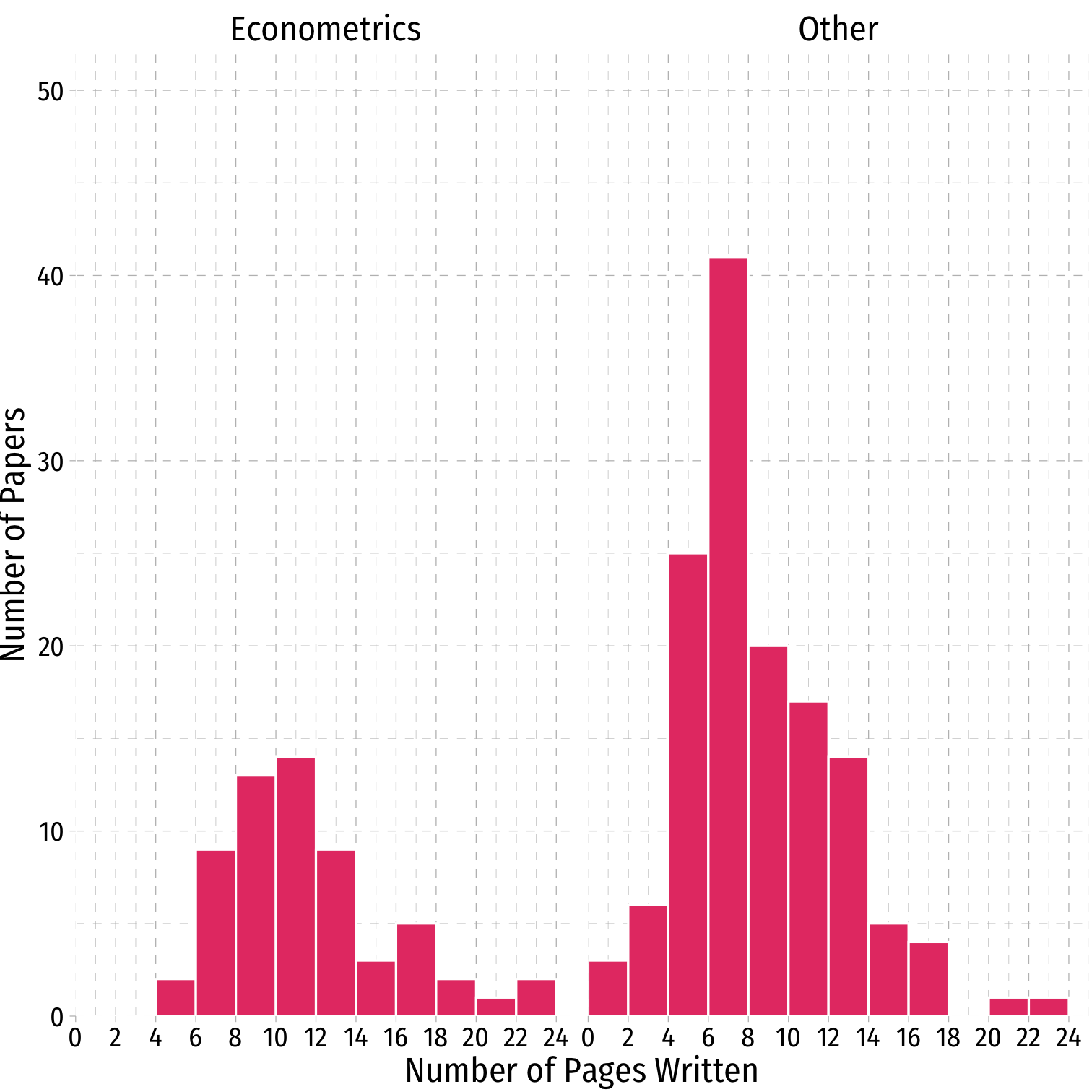
Data: Scatterplot I
Data: Scatterplot II
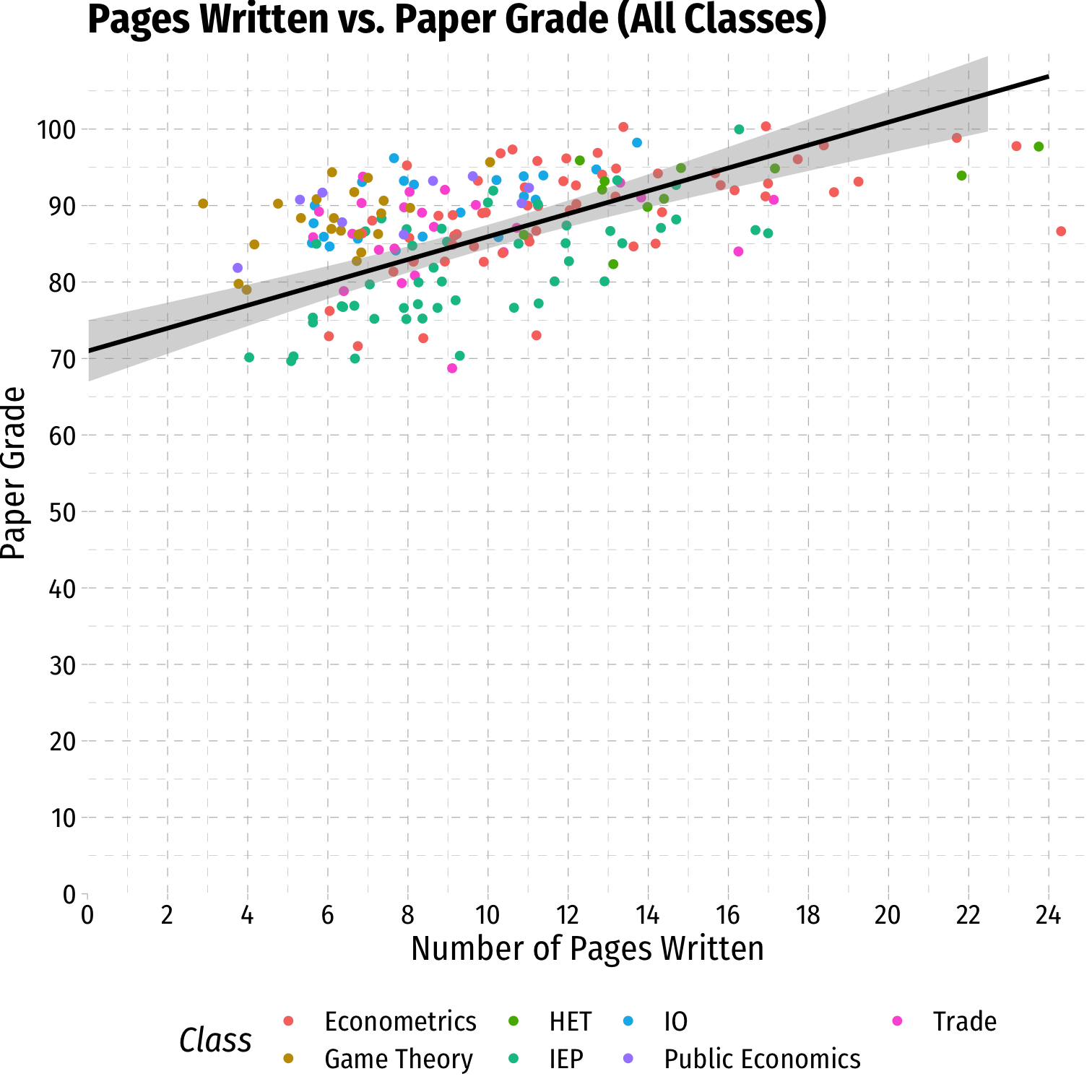
Data: Scatterplot III
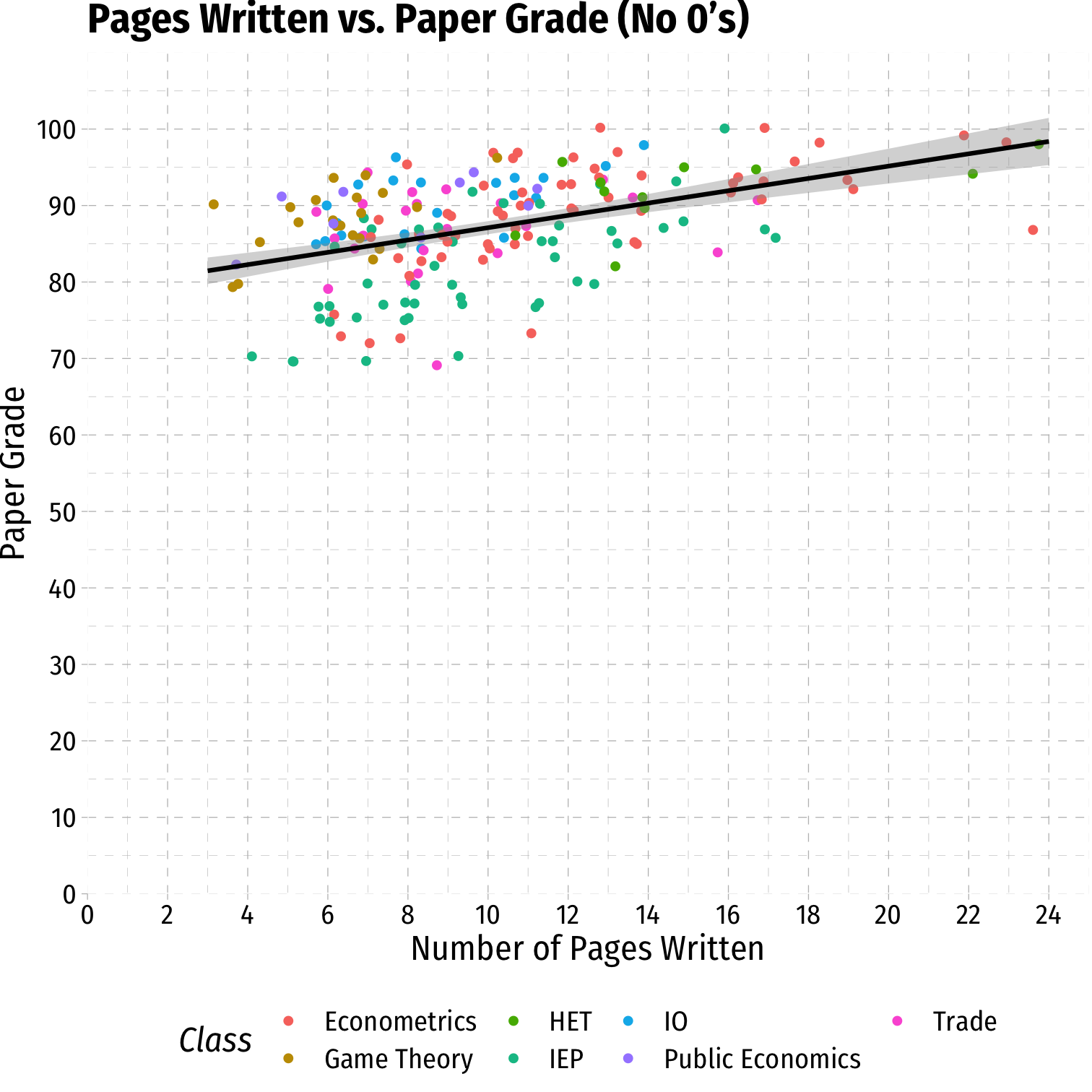
Data: Scatterplot IV
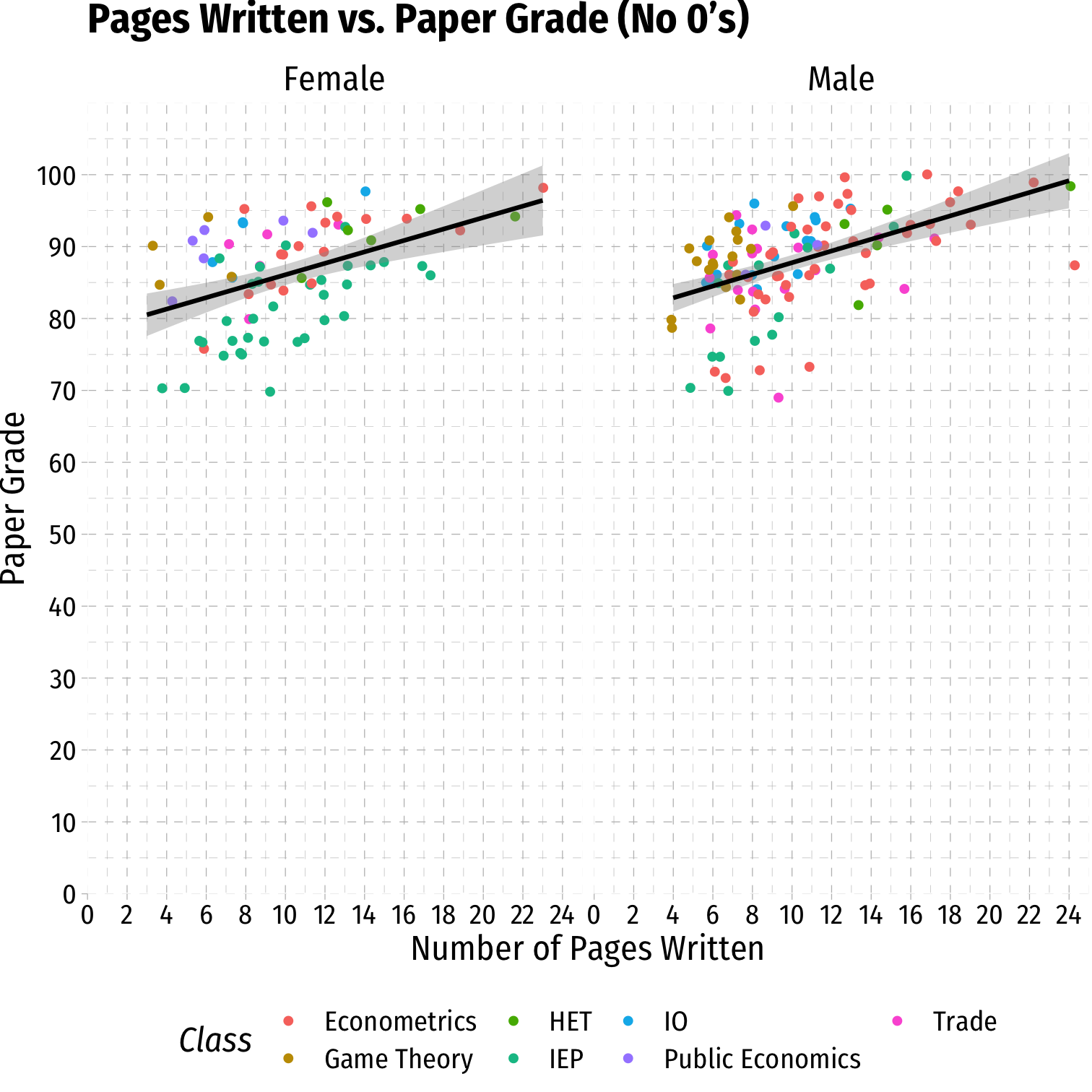
Data: Scatterplot V
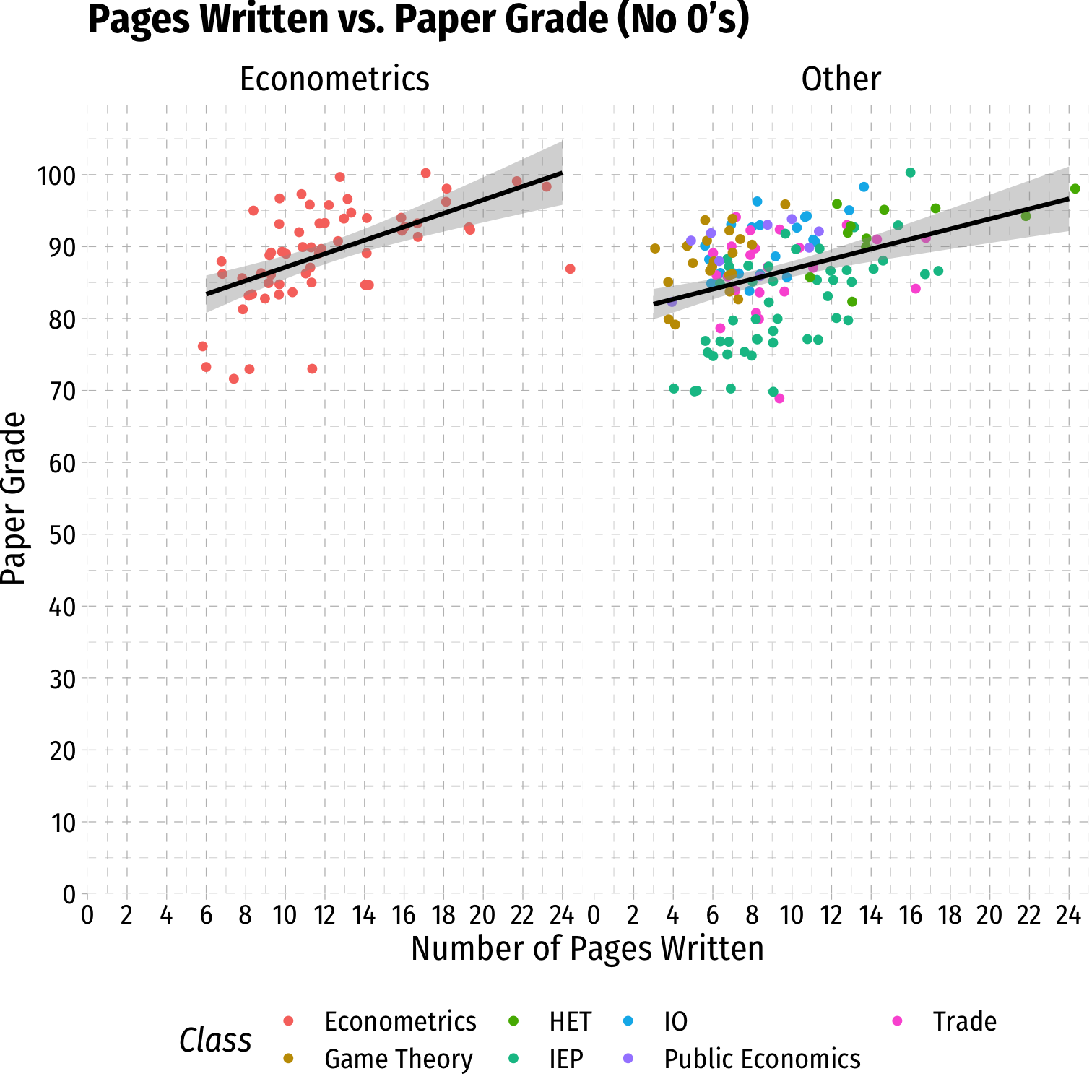
Data: Scatterplot VI
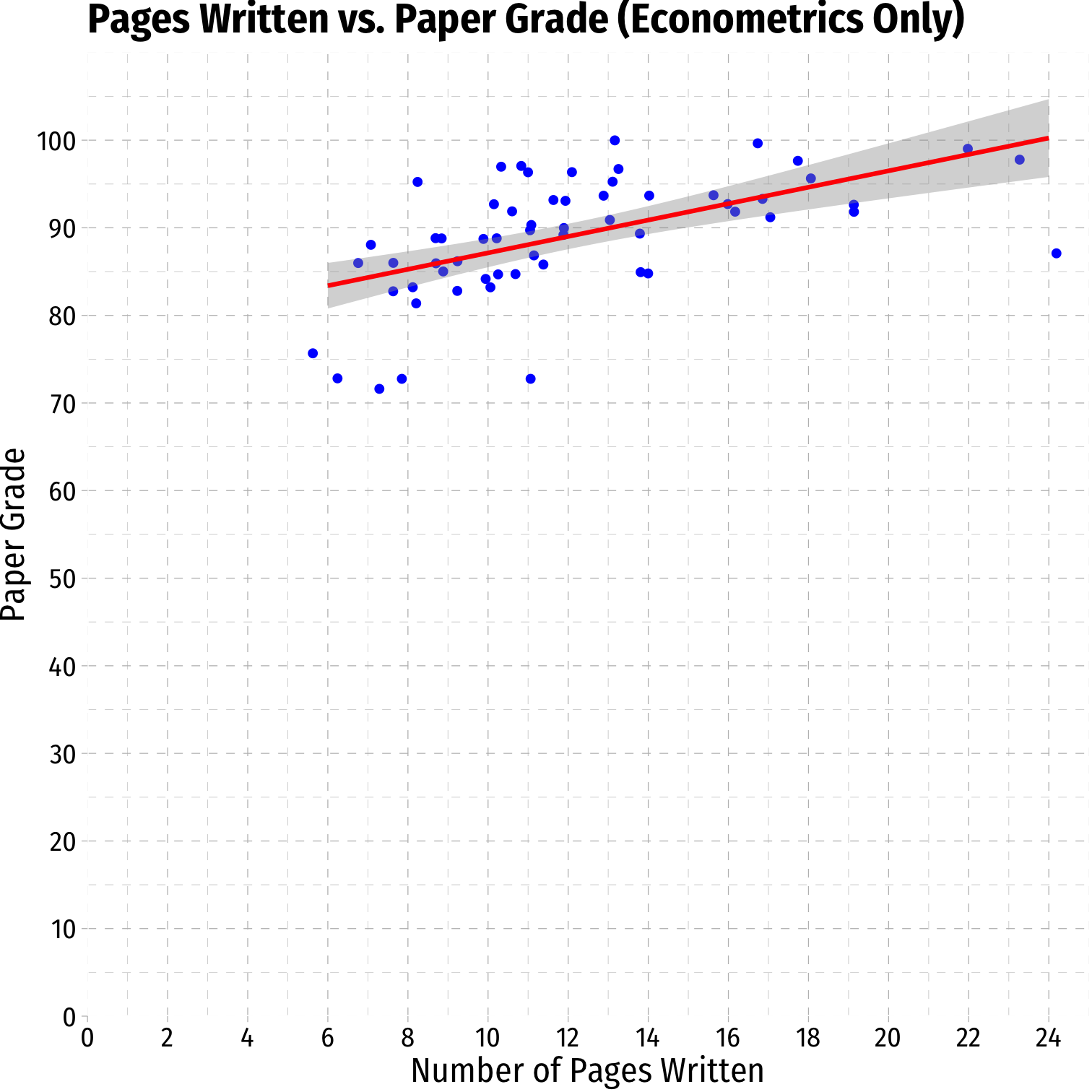
Data: Scatterplot VII
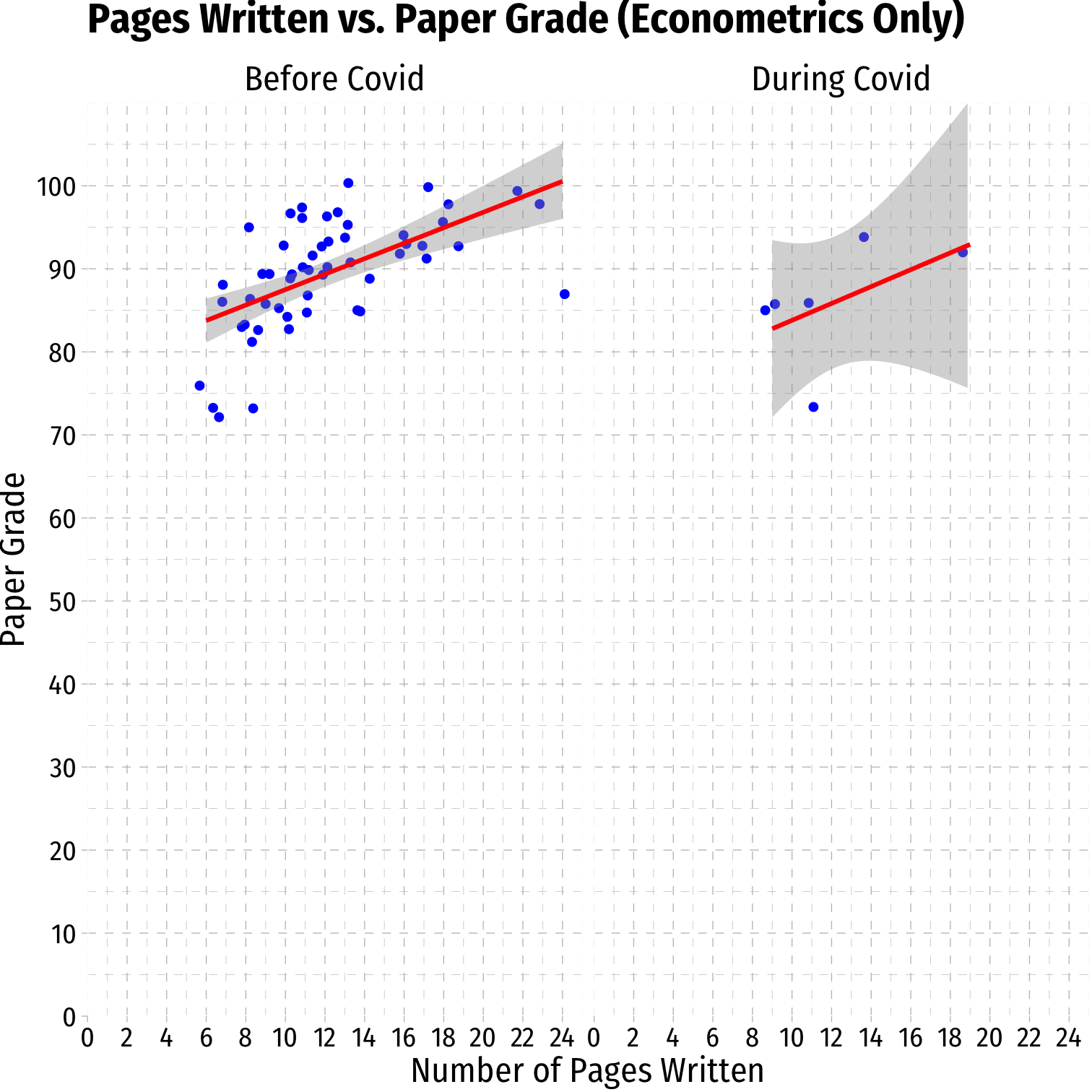
Empirical Model I
Describe your empirical model and your identification strategy
- for most of you, just OLS and trying to include as many controls to remove omitted variable bias
Why did you pick certain variables?
How do you battle endogeneity?
Hypothesize your expected size and magnitude of key variables
- Give some economic intution behind what we would expect!
Empirical Model II
Grade plausibly caused by length (pages), effort, school (uni), gender, course, topic, covid, and time (of day)
Time of day probably unrelated to length...can safely ignore (don’t need to control for)
Don’t have good data on topic
Can’t directly measure for the amount of effort you put in, but I can proxy for it with the final grade in the course (strongly correlated with effort)
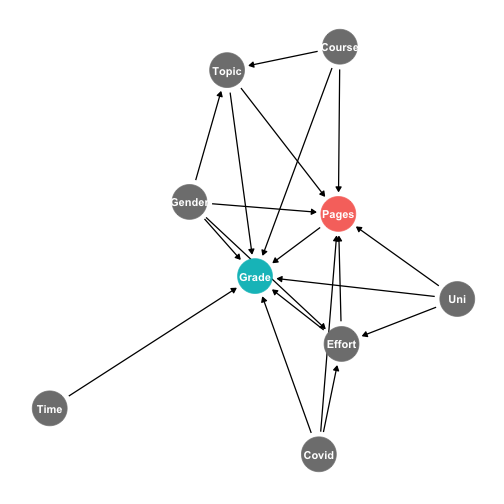
Empirical Model II
- So I need to control for school, course, effort (proxied by final grade), gender, covid, and (if I had data on it...) topic
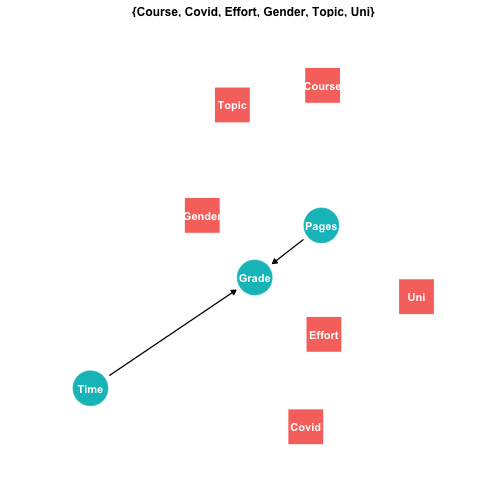
Empirical Model III
Example:
Paper Gradei=β0+β1Paper Lengthi+β2Course Gradei+β3Genderi+β4Schooli+β5Covidi+β6Coursei+ui
Length is the most important variable we care about
Length probably endogenous, correlated with those other Grade-determining factors:
- Why I included these controls!
Likely expect Length to be positive and small
Empirical Model III
Example:
Paper Gradei=β0+β1Paper Lengthi+β2Course Gradei+β3Genderi+β4Schooli+β5Covidi+β6Coursei+ui
You are probably interested specifically in the relationship only for econometrics papers, so we can focus Course specifically to a binary variable Metrics to see how the results differ between non-econometrics courses
Alternatively, we can restrict our sample to only past econometrics classes
Empirical Model IV
- Describe the limitations of your model
- Every paper, even Nobel prize-winning ones, have limitations and problems!
- Limited and/or poor quality data
- Endogeneity, simultaneous causation, omitted variable bias
Example: The model likely suffers from endogeneity, as how many pages a student writes is likely to be positively correlated with personal attributes like diligence, conscientiousness, and intelligence, which themselves are likely positively correlated with the grade of the paper. Thus, we have likely overstated the effect of page length on paper grades. Furthermore, we are unable to measure other variables that make page length endogenous, such as the topic that was chosen. Some topics lend themselves to shorter or longer papers and may have better or worse data that make it easier or difficult to run a clean empirical test.
Empirical Model IV
Are your results robust across different model specifications?
- Do the size(s) of the marginal effect(s) you care about change or reverse direction? Become/lose significance?
At minimum, you must run several models, including a multivariate regression
- Run several variations of your model with and without controls (e.g. just Y and X, Y and X1 and X2, etc.)
- Check for nonlinearities: polynomials, logs, etc.
Results I
Print a table(s) of your regression(s) results
- R packages can help:
huxtable,stargazer,modelsummary
- R packages can help:
Interpret your data (in the text of the paper)
- What does a marginal (1 unit) change in X mean for Y, a 1% change, etc?
- Is each coefficient statistically significant (at 10%, 5%, or 1% levels)?
| Baseline | No Os | Econometrics Only | With Controls | Hood Only | Econometrics Only | |
|---|---|---|---|---|---|---|
| Constant | 70.97 *** | 79.05 *** | 77.77 *** | 50.57 *** | 43.83 *** | 40.66 *** |
| (2.04) | (1.18) | (2.26) | (3.08) | (3.40) | (4.29) | |
| Length | 1.50 *** | 0.81 *** | 0.94 *** | 0.59 *** | 0.33 *** | 0.41 ** |
| (0.19) | (0.11) | (0.18) | (0.10) | (0.09) | (0.13) | |
| Course Grade | 0.29 *** | 0.47 *** | 0.50 *** | |||
| (0.04) | (0.04) | (0.05) | ||||
| Hood College | 6.17 *** | |||||
| (0.97) | ||||||
| Female | -0.38 | -0.28 | -1.02 | |||
| (0.75) | (0.72) | (1.06) | ||||
| Econometrics Course | 1.48 | 0.42 | ||||
| (0.86) | (0.71) | |||||
| During Covid? | -1.64 | -1.72 | -2.72 | |||
| (1.08) | (0.89) | (1.54) | ||||
| N | 197 | 194 | 60 | 194 | 146 | 60 |
| R-Squared | 0.24 | 0.22 | 0.33 | 0.57 | 0.61 | 0.75 |
| SER | 11.05 | 6.03 | 5.61 | 4.57 | 3.66 | 3.53 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||||||
Results I
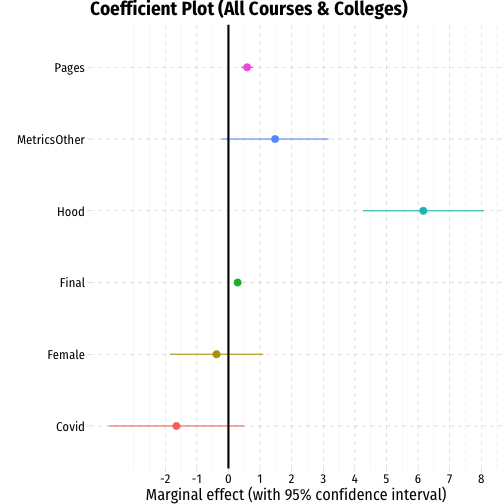
Results I
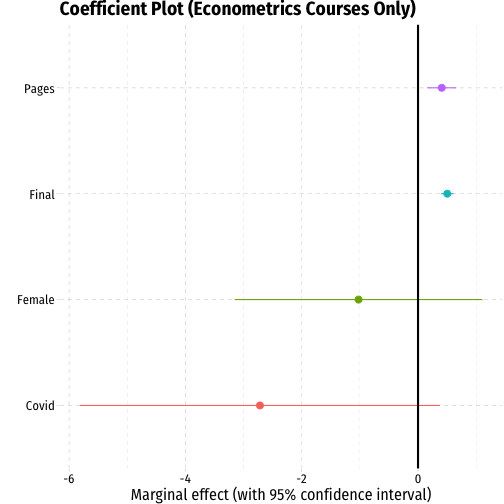
Results: Interpretation!
Are your estimates economically significant?
How big is "big"?
“No economist has achieved scientific success as a result of a statistically significant coefficient. Massed observations, clever common sense, elegant theorems, new policies, sagacious economic reasoning, historical perspective, relevant accounting, these have all led to scientific success. Statistical significance has not.” — McCloskey & Ziliak (1996: 112)
Results: Interpretation!

Results: Interpretation!
Example: I find that for every additional page written, we can expect a paper's grade to increase by about a point or less, after controlling for other factors such as Final grade (proxying as a measure of overall diligence and intelligence), sex, and course. In the most relevant sample, econometrics students, the marginal effect is even smaller, only less than half of a point increase for every additional page written. This small effect is statistically significant at the 10% level only.
However, we should not make much of these results due to the likely endogeneity of Pages due to unobserved factors such as topic and quality of writing, which clearly would matter much both for length and for grade. It would be poor advice to recommend students simply to write long papers to earn a higher grade.
Results: Implications
- Describe several implications of your paper
- Policy implications
- Proposals for new research
- Effects on current understanding
- What else should we try to found out to answer the question better?
Don't Get Discouraged

Don't Get Discouraged

Don't Get Discouraged

Albert Enstein
(1870-1924)
"If we knew what it was we were looking for, we wouldn't call it research, would we?"
Deadlines and Reminders (From the Assignment Page)
| Assignment | Points | Due Date | Description |
|---|---|---|---|
| Abstract | 5 | Fri Oct 22 | Short summary of your ideas |
| Literature Review | 10 | Fri Nov 5 | 1-3 paragraphs on 2-3 scholarly sources |
| Data Description | 10 | Fri Nov 19 | Description of data sources, and some summary statistics |
| Presentation | 5 | Tues/Thurs Nov 30/Dec 2 | Short presentation of your project so far |
| Final Paper Due | 70 | Mon Dec 6 | Email to me paper, data, and code |
- note for each stage (except the Final Paper), it's more than okay that your final topics, data, etc will change!
- for the final paper, I will take 1 point off for every 24 hours it is late
Grading of Final Paper (From the Assignment Page)
| Category | Points |
|---|---|
| Persuasiveness | 10 |
| Clarity | 10 |
| Econometric Validity | 20 |
| Economic Soundness | 20 |
| Organization | 5 |
| References | 5 |
| TOTAL | 70 |
Submitting your Final Paper
When you send your final email (by Tuesday November 22), it should contain the following files:
Your final paper as a
.pdf. It should include an abstract and bibliography and all tables and figures.The (commented!) code used for your data analysis (i.e. loading data, making tables, making plots, running regressions)
- either
.Rfiles OR a.Rmdfile. I want to know how you reached the results you got! Reproducibility is the goal!
- either
Your data used, in whatever original format you found it (e.g.
.csv,.xlsx,.dta)
Some Examples
Example 1
“Exploring the Effects of Children and Marriage on Men’s and Women’s Incomes”
Incomei=β0+β1Number of Childreni+β2Math SAT Scorei+β3Sexi+β4Hours Worked per Weeki+β5Marriedi+ui
- Cross-sectional data for individual i
Example 2
“Does Spending More on the Offensive Line & the Defensive Line Affect NFL Team Wins?”
Winsty=β0+β1OL & DL Spendingty+β2Quarterback Spendingty+β3Defensive Coach Spendingty+αr+τy+ϵit+uty
- Panel data with two way fixed effects for team t in year y;
Example 3
“Buy You a Vote”
Vote Shareit=β0+β1Incumbentit+β2Incumbent Spendingit+β3Non-Incumbent Spendingit+β4Number of Candidatesit+β5Political Partyit+αi+τt+ϵit
- Panel data with two way fixed effects for candidate i at time t
Example 4
“A Cross-Sectional Study on the Effect of State Minimum Wage on Youth Unemployment at the State Level”
ln(Unemployment Rate)i=β0+β1ln(Minimum Wage)i+β2Spending per Studenti+β3Poverty Ratei+ui
- Cross-sectional data for U.S. State i
Example 5
“Is Twitter Strong Enough to Measure NBA Player Performance?”
Player Impact Estimatei=β0+β1ln(Number of Twitter Followers)i+β2Agei+β3Games Playedi+β4Minutes played per gamei+β5Points scored per gamei+β6Salaryi+ui
- Cross-sectional data for player i
Example 5
“The Effect of Economic Growth on Carbon Dioxide Emissions”
lnCO2it=β0+β1lnGDP per capitait+β2lnGDP per capita2it+β3Urbanization Rateit+αi+τt+uit
- A nonlinear (quadratic) model with panel data and two-way fixed effects for country i in time t